CORBA(Common Object Request Broker Architecture)
네 트웍에서 분산 프로그램 객체를 생성, 배포, 관리하기 위한 구조와 규격이며, 네트웍 상의 서로 다른 장소에 있고 여러 벤더들에 의해 개발된 프로그램들이 “인터페이스 브로커”를 통해 통신하도록 해준다. CORBA는 OMG라는 개발자 연합(현재 500여 회원사를 가지고 있다)에서 개발되었다. ISO와 X/Open 양측 모두 CORBA를 분산 객체(컴포넌트로도 알려진)를 위한 표준구조로서 인가하였으며, 현재 CORBA 2.0 이 최신 레벨이다. CORBA의 핵심개념은 ORB이다. 이기종 컴퓨터들의 클라이언트와 서버 네트웍에 대한 ORB 지원이란, 클라이언트 프로그램(객체 자신일 수 있다)이 분산 네트웍에서 서버가 어디 있는지, 또는 서버 프로그램이 어떤 인터페이스를 가질지 인식하지 않고서도, 서버 프로그램이나 객체로부터 서비스를 요구할 수 있다는 것을 의미한다. ORB들간의 요구와 응답을 성립시키기 위해 프로그램들은 GIOP(General Inter-ORB Protocol)를, 인터넷에서는 IIOP를 사용한다. IIOP는 GIOP의 요구와 응답을 각 컴퓨터의 인터넷 TCP 계층으로 대응시킨다. CORBA의 경쟁대상은 독자적인 분산 객체 구조를 가진 마이크로소프트의 DCOM이다. 그러나 CORBA와 마이크로소프트는 게이트웨이를 통해 COM 클라이언트 객체가 CORBA 서버와 통신할 수 있도록 하는데 합의하였다 (그 역방향의 통신도 마찬가지다). 객체지향 프로그래밍과 CORBA를 향한 분산 프로그래밍 구조의 선두주자였던 DCE는 현재 많은 회사에서 사용되고 있다. DCE는 아마 CORBA와 함께 계속 존재할 것이고 둘 사이를 연결시켜 주는 "다리"가 나타날 것이다.
EJB(Enterprise JavaBeans)
클 라이언트/서버 모델의 서버 부분에서 운영되는 자바 프로그램 컴포넌트들을 설정하기 위한 아키텍처이다. EJB는 네트웍 내의 클라이언트들에 분산되어 있는 프로그램 컴포넌트들을 위한 자바빈즈 기술 위에서 구현된다. EJB는 기업들에게, 새로운 프로그램 컴포넌트가 추가되거나 또는 변경될 때마다, 각 개별 컴퓨터를 갱신하지 않고서도 서버에서 변화를 통제할 수 있도록 하는 이점을 제공한다. EJB 컴포넌트들은 다중 응용프로그램들에서 재 사용되는 장점을 가지고 있다. EJB 빈이나 컴포넌트가 배치되기 위해서는 컨테이너라고 불리는 특정 응용프로그램의 일부가 되어야한다. 썬마이크로시스템즈에 의해 비롯된 EJB는, 개략적으로 마이크로소프트의 COM/DCOM 아키텍처에 필적하는 것이다. 그러나, 모든 자바 기반의 아키텍처와 같이, 프로그램들은 윈도우즈뿐만 아니라 모든 주요 운영체계에 걸쳐 배치될 수 있다. EJB의 프로그램 컴포넌트들은 대개 서블릿이라고 알려져 있다. 서블릿을 실행시키는 응용프로그램이나 컨테이너를 때로 애플리케이션 서버라고도 부르는 경우가 있다. 서블릿의 전형적인 용도는 CGI와 Perl 스크립트를 사용하는 웹프로그램을 대체하는 것이다. 또다른 일상적인 용도는 웹사용자와 레거시 메인프레임 응용프로그램과 데이터베이스 사이의 인터페이스를 제공하는 것이다. EJB 내에 두 가지 종류의 빈즈가 있는데, 하나는 세션 빈즈이고 또 하나는 엔터티 빈즈이다. 엔터티 빈즈는 세션 빈즈와 달리, 지속성을 가지고 있으며 원래의 습성이나 상태를 유지할 수 있다.
COM/DCOM(Distributed Component Object Model)
네트웍 상에서 클라이언트 프로그램 객체가 다른 컴퓨터에 있는 서버 프로그램 객체에 서비스를 요청할 수 있도록 해주는 마이크로소프트의 개념이자 프로그램 인터페이스들이다. COM은 같은 컴퓨터(윈도우95나 NT 시스템) 내에서 사용될 수 있도록 클라이언트와 서버에 인터페이스 집합을 제공한다. 예를 들어, 어떤 웹 사이트에 자신의 웹서버가 아닌 다른, 즉 네트웍 상의 보다 특정한 서버에서만 수행되는 스크립트나 프로그램을 가지도록 페이지를 만들 수 있을 것이다. 그 웹사이트의 프로그램(마치 클라이언트 객체처럼 동작하는)은 DCOM 인터페이스를 이용해, 필요한 절차를 수행하고 결과를 웹 서버 사이트에 돌려 주는 특정한 서버 객체에 RPC를 전달할 수 있으며, DCOM은 그 결과를 웹 페이지 뷰어에 넘긴다. DCOM은 또한 대규모 네트웍이나 인터넷과 같은 네트웍 환경에서도 작동할 수 있다. DCOM은 TCP/IP와 HTTP를 사용하며, NT 4.0의 일부가 되었고, 윈도우 95에서 무료로 업그레이드할 수 있다. DCOM은 곧 대부분의 유닉스 플랫폼이나 IBM과 같은 대규모 서버에서도 사용이 가능해질 것이다. DCOM은 OLE Remote Automation을 대체한다. DCOM은 여러가지 분산 서비스들을 제공한다는 차원에서 CORBA와 대등하다. DCOM은 네트웍 환경에서 프로그램과 자료 객체에 대한 마이크로소프트의 접근방식이며, CORBA는 OMG의 후원자들인 그외 나머지 정보통신업계의 지원을 받고있다.
네 트웍에서 분산 프로그램 객체를 생성, 배포, 관리하기 위한 구조와 규격이며, 네트웍 상의 서로 다른 장소에 있고 여러 벤더들에 의해 개발된 프로그램들이 “인터페이스 브로커”를 통해 통신하도록 해준다. CORBA는 OMG라는 개발자 연합(현재 500여 회원사를 가지고 있다)에서 개발되었다. ISO와 X/Open 양측 모두 CORBA를 분산 객체(컴포넌트로도 알려진)를 위한 표준구조로서 인가하였으며, 현재 CORBA 2.0 이 최신 레벨이다. CORBA의 핵심개념은 ORB이다. 이기종 컴퓨터들의 클라이언트와 서버 네트웍에 대한 ORB 지원이란, 클라이언트 프로그램(객체 자신일 수 있다)이 분산 네트웍에서 서버가 어디 있는지, 또는 서버 프로그램이 어떤 인터페이스를 가질지 인식하지 않고서도, 서버 프로그램이나 객체로부터 서비스를 요구할 수 있다는 것을 의미한다. ORB들간의 요구와 응답을 성립시키기 위해 프로그램들은 GIOP(General Inter-ORB Protocol)를, 인터넷에서는 IIOP를 사용한다. IIOP는 GIOP의 요구와 응답을 각 컴퓨터의 인터넷 TCP 계층으로 대응시킨다. CORBA의 경쟁대상은 독자적인 분산 객체 구조를 가진 마이크로소프트의 DCOM이다. 그러나 CORBA와 마이크로소프트는 게이트웨이를 통해 COM 클라이언트 객체가 CORBA 서버와 통신할 수 있도록 하는데 합의하였다 (그 역방향의 통신도 마찬가지다). 객체지향 프로그래밍과 CORBA를 향한 분산 프로그래밍 구조의 선두주자였던 DCE는 현재 많은 회사에서 사용되고 있다. DCE는 아마 CORBA와 함께 계속 존재할 것이고 둘 사이를 연결시켜 주는 "다리"가 나타날 것이다.
EJB(Enterprise JavaBeans)
클 라이언트/서버 모델의 서버 부분에서 운영되는 자바 프로그램 컴포넌트들을 설정하기 위한 아키텍처이다. EJB는 네트웍 내의 클라이언트들에 분산되어 있는 프로그램 컴포넌트들을 위한 자바빈즈 기술 위에서 구현된다. EJB는 기업들에게, 새로운 프로그램 컴포넌트가 추가되거나 또는 변경될 때마다, 각 개별 컴퓨터를 갱신하지 않고서도 서버에서 변화를 통제할 수 있도록 하는 이점을 제공한다. EJB 컴포넌트들은 다중 응용프로그램들에서 재 사용되는 장점을 가지고 있다. EJB 빈이나 컴포넌트가 배치되기 위해서는 컨테이너라고 불리는 특정 응용프로그램의 일부가 되어야한다. 썬마이크로시스템즈에 의해 비롯된 EJB는, 개략적으로 마이크로소프트의 COM/DCOM 아키텍처에 필적하는 것이다. 그러나, 모든 자바 기반의 아키텍처와 같이, 프로그램들은 윈도우즈뿐만 아니라 모든 주요 운영체계에 걸쳐 배치될 수 있다. EJB의 프로그램 컴포넌트들은 대개 서블릿이라고 알려져 있다. 서블릿을 실행시키는 응용프로그램이나 컨테이너를 때로 애플리케이션 서버라고도 부르는 경우가 있다. 서블릿의 전형적인 용도는 CGI와 Perl 스크립트를 사용하는 웹프로그램을 대체하는 것이다. 또다른 일상적인 용도는 웹사용자와 레거시 메인프레임 응용프로그램과 데이터베이스 사이의 인터페이스를 제공하는 것이다. EJB 내에 두 가지 종류의 빈즈가 있는데, 하나는 세션 빈즈이고 또 하나는 엔터티 빈즈이다. 엔터티 빈즈는 세션 빈즈와 달리, 지속성을 가지고 있으며 원래의 습성이나 상태를 유지할 수 있다.
COM/DCOM(Distributed Component Object Model)
네트웍 상에서 클라이언트 프로그램 객체가 다른 컴퓨터에 있는 서버 프로그램 객체에 서비스를 요청할 수 있도록 해주는 마이크로소프트의 개념이자 프로그램 인터페이스들이다. COM은 같은 컴퓨터(윈도우95나 NT 시스템) 내에서 사용될 수 있도록 클라이언트와 서버에 인터페이스 집합을 제공한다. 예를 들어, 어떤 웹 사이트에 자신의 웹서버가 아닌 다른, 즉 네트웍 상의 보다 특정한 서버에서만 수행되는 스크립트나 프로그램을 가지도록 페이지를 만들 수 있을 것이다. 그 웹사이트의 프로그램(마치 클라이언트 객체처럼 동작하는)은 DCOM 인터페이스를 이용해, 필요한 절차를 수행하고 결과를 웹 서버 사이트에 돌려 주는 특정한 서버 객체에 RPC를 전달할 수 있으며, DCOM은 그 결과를 웹 페이지 뷰어에 넘긴다. DCOM은 또한 대규모 네트웍이나 인터넷과 같은 네트웍 환경에서도 작동할 수 있다. DCOM은 TCP/IP와 HTTP를 사용하며, NT 4.0의 일부가 되었고, 윈도우 95에서 무료로 업그레이드할 수 있다. DCOM은 곧 대부분의 유닉스 플랫폼이나 IBM과 같은 대규모 서버에서도 사용이 가능해질 것이다. DCOM은 OLE Remote Automation을 대체한다. DCOM은 여러가지 분산 서비스들을 제공한다는 차원에서 CORBA와 대등하다. DCOM은 네트웍 환경에서 프로그램과 자료 객체에 대한 마이크로소프트의 접근방식이며, CORBA는 OMG의 후원자들인 그외 나머지 정보통신업계의 지원을 받고있다.


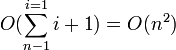 이 된다.
이 된다.



