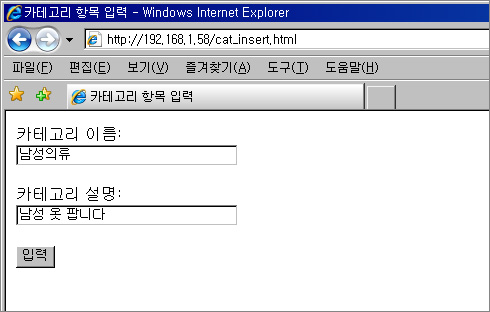
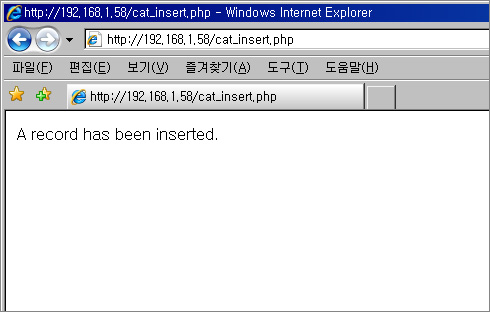
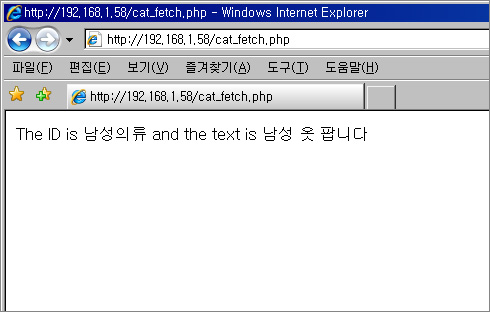
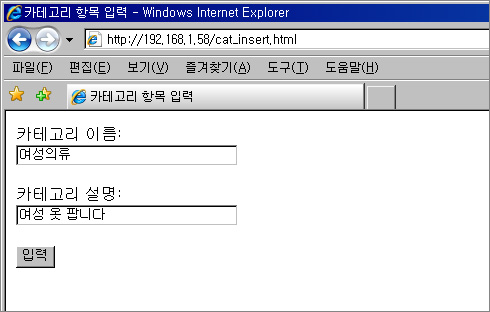
리눅스에서 Apache2.2.4 + PHP 5.2.3 + mysql 5.1.19 설치
아파치와 PHP 소스 파일을 다운로드 받아 설치하는 방법을 설명한다. PHP 5.x에서 mysql을 사용하기 위해서는 반드시 컴파일 과정을 거쳐야 하므로 RPM을 이용한 설치에는 한계가 있다.
1. 준비사항
1-1. PHP 소스 파일 : http://www.php.net 에 접속하여 상단 메뉴 중 downloads를 클릭한다.(http://www.php.net/downloads.php 에 바로 접속할 수도 있다.)
PHP 5.2.3
Complete Source Code
PHP 5.2.3 (tar.gz) [9,123Kb] - 01 June 2007를 클릭하여 소스 코드를 다운로드 받는다.
미러링 사이트 중 Repoublic of Korea kr2.php.net HANBIRO에서 다운로드 하였다면, 다운로드 된 파일 이름은 php-5.2.3.tar.tar 이다.
1-2. 아파치 소스 파일 : http://httpd.apache.org/에 접속하여 Download! from a mirror를 클릭하면(http://httpd.apache.org/download.cgi 에 바로 접속할 수도 있다) 미러링 사이트로 KAIST가 자동 선택된다. 이곳에서 Unix Source: httpd-2.2.4.tar.gz를 클릭 하여 다운로드 받는다. 다운로드 된 파일 이름은 httpd-2.2.4.tar.gz 이다.
1-3. PHP 설치를 위한 XML 확장 설치
PHP 5부터 PHP에서 XML을 지원하기 위해 XML 확장을 설치해야 한다. 이에 따라 필요 라이브러리를 설치한다.
PHP5에서 XML 확장을 위해서 libxml2 와 libxslt 라이브러리를 설치해야 하는데, libxml2에서 zlib와 iconv 라이브러리를 필요로 하므로 이들 라이브러리의 설치가 선행되어야 한다.
1-3-1. zlib : 공식 사이트는 http://www.zlib.net 이다. 이곳에서 zlib source code, version 1.2.3, tar.gz format을 다운로드 받는다.
US(www.zlib.net)에서 다운로드 받을 수 있으며 다른 미러링 사이트를 이용할 수도 있다. 다운로드된 파일 이름은 zlib-1.2.3.tar.tar 이다.
1-3-2. libconv : 에서 libconv를 다운로드 받을 수 있다. 이 문서는 업데이트가 늦은 관계로 The Latest release is biconv-1.11.tar.gz 로 되어 있지만, 이 링크를 클릭하여 다운로드 받으면 안된다. 앞서 받은 라이브러리의 버전이 최신 이므로 libiconv 역시 최신 버전은 1.9.1을 받아야 한다. 다운로드 받는 방법은 위에 표시되어 있는 libiconv-1.11.tar.gz 에서 파일 이름을 삭제 하면 디렉터리 리스트를 볼 수 있는데, 이곳에서 최신 버전의 소스를 다운로드 받는다. 즉 http://ftp.gnu.org/pub/gnu/libiconv/ 에 접속해서 libiconv-1.9.1.tar.gz를 다운로드 받는다.
다운로드 된 파일은 libiconv-1.9.2.tar.tar 이다.
1-3-3. libxml2 : 에서 libxml2 소스 최신 버전을 다운로드 받는다. 현재 최신 버전은 libxml2-2.6.29.tar.gz 이다. 다운로드 된 파일은 libxml2-2.6.29.tar.gz
1-3-4. libxslt : 에서 libxslt 소스 최신 버전을 다운로드 받는다. 현재 최신 버전은 libxslt-1.1.9.tar.gz 이다. 다운로드 된 파일은 libxslt-1.1.9.tar.gz 이다.
1-4. MySQL 설치 (MySQL은 5.0.37을 이용하였다)
http://www.mysql.com 에 접속하여 mysql 소스를 다운로드 받아 설치한다. mySQL은 두 가지 라이센스를 사용한다. 상업용으로 사용을 하기 위해서는 MySQL Enterprise를 구매해야 한다. 개발자용은 MySQL Community Server를 다운로드 받아 사용할 수 있다. http://www.mysql.com 에 접속하여 우측 사각형에서 MySQL Cmmunity Server Download를 클릭한다. 기본적으로 MySQL 5.0 Downloads에 접속하며, 여기에서 페이지 최 하단에 있는 Source downloads 항목에서 compressed GNU TAR archive(tar.gz)를 다운로드 받는다. 이 페이지에서 다운로드 받거나, 만일 다운로드에 성공하지 못하면 Pick a mirror를 선택하여 다른 다운로드 사이트에서 다운로드 받도록 한다. 다운로드 된 파일 이름은 mysql-5.1.19-beta.tar.gz 이다.
이렇게 해서 준비된 파일은 모두 다음과 같다.
php-5.2.3.tar.tar (http://www.php.net/downloads.php)
httpd-2.2.4.tar.gz (http://httpd.apache.org/download.cgi)
zlib-1.2.3.tar.tar (http://www.zlib.net)
libiconv-1.9.2.tar.tar (http://ftp.gnu.org/pub/gnu/libiconv/)
libxml2-2.6.29.tar.gz (http://www.xmlsoft.org/sources/)
libxslt-1.1.9.tar.gz (http://www.xmlsoft.org/sources/)
mysql-5.1.19-beta.tar.gz (http://dev.mysql.com/downloads/mysql/5.0.html)
2. 설치
패키지의 설치이므로 root 권한으로 접속한다. 다운로드 패키지는 모두 /root/down/ 디렉터리에 존재하며, 설치는 /usr/local/ 에 설치하도록 한다.
2-1. 아파치 설치
2-1-1 아파치 압축 풀기
[root@ns down]# tar xvfz httpd-2.2.4
2-1-2 아파치 컴파일 및 설치
PHP를 아파치 2.2의 모듈로 다이나믹 로딩 하려면 아파치 서버가 DSO(Dynamic Shared Object)를 지원하도록 컴파일 해야 한다. 이를 위해 --enable-so 옵션을 사용하여 configure를 실행한다.
[root@ns down]# cd httpd-2.2.4
[root@ns httpd-2.2.4]# ./configure --enable-so
--prefix=[DIR] 옵션을 사용하여 원하는 위치에 설치할 수도 있으나, 앞서 전제 조건이 /usr/local/ 디렉토리에 설치하기로 했으므로 추가 옵션을 없어도 가능하다. 옵션 없이 설치 시 /usr/local/apache2 에 설치된다.
[root@ns httpd-2.2.4]# make
[root@ns httpd-2.2.4]# make install
설치가 완료 되었다. /usr/local/apache2 디렉터리로 이동하여 설치를 확인한다.
[root@ns httpd-2.2.4]# cd /usr/local/apache2/bin/
[root@ns bin]# ./apachectl start
※ 이미 아파치가 실행되고 있는 상태라면
[root@ns ~]#service httpd stop 으로 아파치의 구동을 종료한 후 실행한다.
2-2. zlib 설치
2-2-1 zlib 압축 해제
[root@ns down]# tar xvfz zlib-1.2.3.tar.tar
2-2-2 zlib 컴파일 및 설치
[root@ns down]# cd zlib-1.2.3
[root@ns zlib-1.2.3]# ./configure --prefix=/usr/local/
[root@ns zlib-1.2.3]# make
[root@ns zlib-1.2.3]# make install
2-3. libconv 설치
2-3-1 libiconv 압축 해제
[root@ns down]# tar xvfz libiconv-1.9.2.tar.tar
2-3-2 libiconv 컴파일 및 설치
[root@ns down]# cd libiconv-1.9.2
[root@ns libiconv-1.9.2]# ./configure --prefix=/usr/local/
[root@ns libiconv-1.9.2]# make
[root@ns libiconv-1.9.2]# make install
2-4. libxml2 설치
2-4-1 libxml2 압축 해제
[root@ns down]# tar xvfz libxml2-2.6.29.tar.gz
2-4-2 libxml2 컴파일 및 설치
[root@ns down]# cd libxml2-2.6.29
[root@ns llibxml2-2.6.29]# ./configure \
>--prefix=/usr/local/ \
>--with-zlib=/usr/local/ \
>--with-iconv=/usr/local/
[root@ns llibxml2-2.6.29]# make
[root@ns llibxml2-2.6.29]# make install
2-5. libxslt 설치
2-5-1 libxslt 압축 해제
[root@ns down]# tar xvfz libxslt-1.1.9.tar.gz
2-5-2 libxslt 컴파일 및 설치
[root@ns down]# cd libxslt-1.1.9
[root@ns libxslt-1.1.9]# ./configure --prefix=/usr/local/ \
> --with-libxml-prefix=/usr/local/ \
> --with-libxml-include-prefix=/usr/local/include/ \
> --with-libxml-libs-prefix=/usr/local/lib
[root@ns libxslt-1.1.9]# make
[root@ns libxslt-1.1.9]# make install
2-6. MySQL의 설치
MySQL을 설치하기 위하여 mysql group 의 생성 및 mysql 사용자 계정의 생성이 선행 되어야 하지만, 대부분의 경우 linux를 설치할 때 mysql을 설치하므로 이때 mysql 관련 그룹 및 계정이 생성된다. 이미 계정이 생성되어 있다면 새로 생성할 필요는 없다.
설치할 디렉터리는 /user/local/mysql 이므로 mysql 디렉터리를 미리 생성해 둔다.
[root@ns ~]# mkdir /usr/local/mysql
[root@ns ~]# groupadd mysql
[root@ns ~]# useradd -g mysql mysql
2-6-1 MySQL 압축 해제
[root@ns down]# tar xvfz mysql-5.1.19-beta.tar.gz
[root@ns down]# cd mysql-5.1.19-beta
2-6-2 MySQL 컴파일 및 설치
[root@ns mysql-5.1.19-beta]# ./configure --prefix=/usr/local/mysql/ \
>--with-mysqld-user=mysql \
>--without-debug
[root@ns mysql-5.1.19-beta]# make
[root@ns mysql-5.1.19-beta]# make install
설치가 끝나면, mysql_install_db를 실행하여 mysql 시스템 데이터 베이스와 test 데이터 베이스를 생성한다.
[root@ns mysql-5.1.19-beta]# cd /usr/local/mysql/bin
[root@ns bin]# ./mysql_install_db
/usr/local/mysql 디렉터리의 소유권을 root로 설정하고, MySQL data 디렉터리의 소유권을 mysql 사용자로 변경한다. 보안을 위해 설정하는 부분이다.
[root@ns ~]# chown -R root /usr/local/mysql
[root@ns ~]# chown -R mysql /usr/local/mysql/var
[root@ns ~]# chgrp -R mysql /usr/local/mysql
my.cnf 파일을 생성한다. MySQL 서버에서 환경 설정을 위한 파일이다.
[root@ns ~]#cp /usr/local/mysql/share/my-large.cnf /etc/my.cnf
※ 자신의 환경에 맞게 적당한 파일을 복사하면 된다.
[root@ns ~]# ls /usr/local/mysql/share/mysql/my*.cnf
/usr/local/mysql/share/mysql/my-huge.cnf
/usr/local/mysql/share/mysql/my-innodb-heavy-4G.cnf
/usr/local/mysql/share/mysql/my-large.cnf
/usr/local/mysql/share/mysql/my-medium.cnf
/usr/local/mysql/share/mysql/my-small.cnf
2-6-3 MySQL 서버의 구동 및 정지
[root@ns ~]# /usr/local/mysql/bin/mysqld_safe --user=mysql &
※ 이미 mysqld 데몬이 구동 중이면 우선 데몬을 중지 시킨다.
[root@ns ~]# service mysqld stop
mysql을 정지시키고자 한다면 다음 명령어를 입력한다.
[root@ns ~]# /usr/local/mysql/bin/mysqladmin shutdown
다시 시작하려면 위에서 설명한 대로 mysql_safe를 실행한다.
2-6-4 root 패스워드 변경 및 일반 사용자 계정 생성
이제 접속 하여서 root의 패스워드를 바꾸고 사용자 계정을 생성하도록 하자.
(이미 mysql이 설치되어 있다면 기존의 mysql 클라이언트를 이용해도 상관은 없다.)
[root@ns ~]#mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 115 to server version: 5.1.19-beta-log
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> use mysql
Database changed
mysql> select user, host, password
-> from user;
+------+-------------+-------------------- ------------------+
| user | host | password |
+------+--------------+----------------- -------------------+
| root | localhost | +
| root | ns.ifoxrose.com | |
| root | 127.0.0.1 | |
+------+-------------+----------------------------------------+
3 rows in set (0.00 sec)
mysql> update user
-> set password = password('**********')
-> where user = 'root';
Query OK, 3 rows affected (0.00 sec)
Rows matched: 3 Changed: 3 Warnings: 0
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> create database database_name;
Query OK, 1 row affected (0.00 sec)
mysql> grant all privileges on database_name to user_name identified by 'user_password';
Query OK, 0 rows affected (0.00 sec)
※일반적으로 mysql에서 데이터베이스 명과 계정명을 동일하게 준다.
mysql> exit
Bye
생성한 계정으로 접속을 시도해 본다.
[root@ns ~]# mysql -utest_user -p
Enter password:*********
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 116 to server version: 5.1.19-beta-log
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql>
2-7. PHP의 설치
Share Apache 2.0 Handler module을 생성하기 위해 --with-apxs2[=FILE]을 사용한다. [FILE] 은 앞에서 설치한 Apache 디렉터리의 bin 디렉터리의 apxs파일을 이용한다. (--with-apxs2=/usr/local/apache2/bin/apxs)
또한 xml 확장 사용을 명시 하고(--with-xml) 앞서 설치한 libxml, xsl, dom, iconv 등의디렉터리를 설정하고, socket 프로그래밍에 사용할 수 있도록 --enable-sockets 옵션을 설정한다.
우리가 소스로 설치를 한 이유였던 데이터베이스 사용 설정을 추가해야 하는데, DBX를 사용하기 위한 옵션은 --enable-dbx 옵션이다. 물론 사용하고자 하는 데이터베이스에 대한 옵션을 넣어 주어야 하는데, mysql 의 경우 --with-mysql=[DIR] 이며, 오라클의 경우 --with-oracle=[DIR] 이다. mysql ext/mysqli 확장을 사용하고자 한다면 --with-mysqli 옵션을 추가한다. 이 과정을 순서대로 하면 다음과 같다.
2-7-1 libxslt 압축 해제
[root@ns down]# tar xvfz php-5.2.3.tar.tar
2-7-2 PHP 컴파일 및 설치
[root@ns down]# cd php-5.2.3
[root@ns php-5.2.3]#./configure --with-apxs2=/usr/local/apache2/bin/apxs \
>--with-zlib-dir=/usr/local/ \
>--with-xml \
>--with-libxml-dir=/usr/local/ \
>--with-xsl=/usr/local/ \
>--with-dom=/usr/local/ \
>--with-iconv \
>--enable-sockets \
>--enable-dbx \
>--with-mysql=/usr/local/mysql/ \
>--with-mysqli --with-oracle=/app/oracle/
※ 추가적인 설정을 보려면 ./configure --help를 이용한다.
[root@ns php-5.2.3]# make
[root@ns php-5.2.3]# make install
설치를 마치고 나면 Apacehe 와 PHP의 추가적인 설정이 필요 하다. 우선 php의 압축 해제 디렉터리에 있는 php.ini-dist 혹은 php.ini-recommended 파일 중 하나를 선택하여 php.ini 파일을 생성한다. php.ini-recommended 파일은 성능 향상을 낼 수 있도록 값이 조정되어 있는 파일이지만, 자신의 환경에 맞도록 설정해야 한다. 다음 예는 php.ini-dist 파일을 복사한 예이다. 물론 이미 잘 구동되고 있는 /etc/php.ini 파일을 복사해서 사용해도 된다.
[root@ns php-5.2.3]# ls php.ini*
php.ini-dist php.ini-recommended
[root@ns php-5.2.3]# cp php.ini-dist /usr/local/apache2/conf/php.ini
아파치를 구동해 보도록 하자
[root@ns bin]# /usr/local/apache2/bin/apachectl start
만일 일반 접속은 가능한데, 일반 사용자 접속이 불가능 하다면, /usr/local/apache2/conf/httpd.conf 파일에서 다음 내용을 검색해서 주석을 없애 준다.
# User home directories
# Include conf/extra/httpd-userdir.conf ; 주석을 없애서 다음과 같이 만든다.
# User home directories
Include conf/extra/httpd-userdir.conf
일반 사용자 계정의 html 문서가 정상적으로 동작 할 것이다. 이제 간단한 php 프로그램이 동작하는 지 살펴 보고 만일 동작하지 않는다면, httpd.conf 파일에 다음과 같이 AppType application/x-httpd-php .php .php4 .php5 등을 추가해 준다.
<IfModule mime_module>
#
# TypesConfig points to the file containing the list of mappings from
# filename extension to MIME-type.
#
TypesConfig conf/mime.types
…중략 …
AddType application/x-compress .Z
AddType application/x-gzip .gz .tgz
# 추가된 부분
AddType application/x-httpd-php .php .phtml .php3 .php5