'분류 전체보기'에 해당되는 글 304건
- 2008.08.04 double push
- 2008.08.04 Cross over
- 2008.08.04 push(2)
- 2008.08.04 push(2)
- 2008.08.01 expression pattern
- 2008.08.01 script class
- 2008.08.01 정규화
- 2008.08.01 deadlock 4가지
- 2008.08.01 B-, B+ Tree
- 2008.08.01 CPU scheduling
| 한 발에 체중을 실어서 인엣지와 아웃엣지로 주행하는 방법을 마스터했다면 다음은 크로스오버를 배워봅니다. 기본은 같습니다. 한쪽 발에 몸의 중심을 실어 원심력을 이용해 발을 교차시키면서 회전합니다. 이렇게 하면 스피드를 더욱 높일 수 있습니다. 팔도 같이 흔들면서 균형을 잡는 것도 잊지 않으면서 연습하도록 하세요. | ||||
 | ||||
① 허리를 숙이고 무릎, 발목을 확실히 굽혀줍니다. 그리고 교차하는 앞발을 가깝게 두는 것이 중요합니다. ... 발을 두는 위치가 멀리 있으면 균형이 흐트러지는 원인이 됩니다. ② 평행하게 발을 둡니다. ③ 오른쪽 어깨가 안쪽으로 들어가지 않도록 주의합니다. ④ 여기에서는 가능한 왼쪽 발을 굽혀서 지치는 준비를 합니다. ⑤ 오른쪽 팔을 강하게 흔들면서 원심력의 반대로 힘을 가합니다. 원심력에 지지 않도록 확실히 흔들어서 ... 몸 전체의 균형을 잡습니다. ⑥ 그리고 한쪽발로 중심을 잡습니다. | ||||
| ||||
⑤ 반대의 교차도 요령은 같습니다. 당겨 붙여두었던 뒷발을 지금까지 중심이 놓여있었던 앞발의 바로 앞에 ....가져다 옵니다. ....이 경우도 너무 멀리에 떨어뜨려 두지 않고 가능한 가깝고 평행하게 두는 것이 포인트입니다. ⑥ 코에서부터 배꼽, 앞 무릎 그리고 엄지발가락이 일직선이 되도록 합니다. ⑦ 완전히 한쪽발로 주행을 하면서 위의 동작을 반복합니다. | ||||


'inline' 카테고리의 다른 글
| double push (0) | 2008.08.04 |
|---|---|
| push(2) (0) | 2008.08.04 |
| push(2) (0) | 2008.08.04 |
인라인 기술에 관련된 칼럼을 쓰는 것은 만 3년만입니다. 3년전에 파스칼의 더블푸쉬를 분석했던 것 이 후로 기술적인 부분에 대해서 칼럼은 잘 쓰지 않았습니다. 그것은 인라인을 알면 알수록 제 지식이 미천함을 깨닫게 되었기 때문일 것입니다
※ 내용을 퍼가실 땐
 기능을 이용해 주시기 바랍니다. 복사해서 가져가시면 향후 수정하는 내용이 반영되지 않기 때문입니다.
기능을 이용해 주시기 바랍니다. 복사해서 가져가시면 향후 수정하는 내용이 반영되지 않기 때문입니다. 1. 효율적인 푸쉬(1) - fall
아마추어 인라인 레이서들의 주 관심사는 어떻게 더 적은 체력으로 더 먼거리를(또는 더 빠르게) 갈 것인가 하는 효율에 대한 것이다. 이것은 마라톤과 로드런 위주로 발전한 인라인 문화의 영향일 것이다.
효율적인 푸쉬를 위해서는 중력을 최대한 이용해야하며 중력을 추진력으로 변환하는 동작이 '체중 떨어뜨리기'(fall)이다. (최근 한홍희님이 언급한 '넘어지기', 이왕중님이 오래전부터 설명하는 '쓰러지기'가 다 이 fall동작이다. 땅에 넘어지는 동작과 구분하기 위해 fall이란 용어를 그대로 사용하고자한다. 영어알레르기가 있는 분들의 양해를 바람.)
체중이 중력에 의해서 땅에 떨어지려는 힘이 fall동작에 의해서 횡방향의 힘을 만들어 낸다.
먼저 그림으로 중력이 어떻게 추진력으로 변환되는지 알아보자.
그림1.1. 푸쉬 = 중력에 의한 추진(fall) + 근력에 의한 추진(밀기) [사진: 허유빈 데몬]
푸쉬동작은 중력에 의한 추진(fall)와 다리 근력에 의한 추진(밀기)로 이루어진다.
초급자일수록 다리 근력에 의지하여 추진력을 발생시키며, 상급자는 상황에 따라 두 가지 추진력의 비율을 자유롭게 조절할 수 있다. (초급자가 다리 근력에만 의지하는 이유가 체중이 추진력을 만들어내는 원리와 그 느낌을 이해하지 못하기 때문이고 그것을 쉽게 설명하려는 것이 본 글의 목적이다.)
본 글은 효율적인 푸쉬에 대한 내용이므로 근력을 최소한 사용하고 체중을 최대한 활용하는 쪽에 초점을 맞추고자 한다.
fall 동작을 풀어 말하면 무게중심(COM:center of mass)을 축발(BOS:base of support)으로부터 횡방향으로 멀어지게 하여 중력에 의해 떨어뜨리는 것이다. 무게중심이 축발을 벗어날 수록 불안정해지고 넘어지기 직전에 위치에너지가 최대 운동에너지를 만들어낸다.
즉, 무게중심(골반)이 충분히 움직여야 큰 추진력을 얻을 수 있고, 이 것이 안될 때 '체중이동이 안된다'라고 말한다.
다음은 fall동작이 전혀없는 전형적인 초급자의 동작과 fall동작이 잘 보이도록 과장한 동작이다.
빨강, 파랑, 녹색 세개의 원은 양발과 무게중심의 위치를 의미한다.
그림1.2. (좌)fall이 전혀 안되는 푸쉬 (우) fall 동작
그림1.3. 두 발과 무게중심의 표시 방법 [사진: 정소영 데몬]
두가지 동작의 차이점은 축발을 먼저 내려놓고 푸쉬를 하는가 아니면 최대한 축발을 늦게 내려놓는 가이다. 축발을 땅에 늦게 내려놓을 수록 낙차가 커지고 큰 추진력을 얻게 된다.
fall동작이 무엇인지 이해가 되었다면 다음 동영상을 통해 실제 주행에서의 fall을 이해할 수 있을 것이다.
다은은 에디 매츠거의 주행 영상에 fall 동작을 표시한 것이다.
그림1.4. 살로몬, 데스티네이션 스피드 中
'데스티네이션 스피드'에서 에디는 '이 자세는 장거리에 적합하고 특히 혼자 달리거나 선두에서 달릴때 최소한의 체력으로 스피드를 유지할 수 있다. 셋 다운을 늦게하고 체중이 떨어지는 힘을 푸쉬하는 발에 집중시켜야한다.'라고 설명한다. 다소 과장된 에디의 주행자세에서 fall동작을 쉽게 발견할 수 있다.
본 글에서는 적은 체력 소비하고 효율적으로 주행을 할 수 있는 fall 동작에 대해서 알아보았다.
이는 특히 레이싱 초급자들이 간과하는 부분이다.
다음에는 효율적인 푸쉬 두번째 팁으로 푸쉬 방향에 대해서 설명할 것이다.
'inline' 카테고리의 다른 글
| double push (0) | 2008.08.04 |
|---|---|
| Cross over (0) | 2008.08.04 |
| push(2) (0) | 2008.08.04 |

지난번 칼럼에 대한 많은 분들의 관심 감사합니다. 그리고 설명이 부족했던 부분에 대해 부연설명을 해주신 분들께도 감사의 말씀을 전합니다. 제가 바랬던 것처럼 여러분과 함께 연구하고 보완하는 칼럼이 된 것 같아 보람을 느낍니다
퍼가실 때 기능을 사용하시면 앞으로 추가 될 의견들과 보완 될 내용이 그대로 반영됩니다.
효율적인 푸쉬(2) – 푸쉬의 방향
두 번째 주제로 푸쉬 방향을 선택한 이유는 푸쉬 방향이 오랜 동안 논란의 대상이 되었고 그 과정에서 고정관념이 형성되어 바람직하지 않은 영향도 미치고 있다고 생각하기 때문이다. 효율적인 푸쉬 방향은 분명 존재 할 것이다. 그러나, 이 방향(각도)는 단순히 다리의 움직임에 의한 것이 아니라 여러 동작들이 서로 영향을 미쳐 만들어낸 결과이며 속도에 따라 달라지며 스케이팅 스타일이나 신체조건에 따라서도 달라지게 된다. 따라서, 그 원리와 과정을 생략하고 단순히 푸쉬의 방향만을 따지는 것은 바람직하지 않다.
상급자들의 경우 푸쉬의 방향에 자체에 대해서 큰 의미를 두지 않는다. 충분한 가속을 얻을 수 있는지 여부가 중요한 것이며, 어떤 순간에 어느 방향으로 밀어야 하는지는 경험과 감각으로 판단하게 된다.
본 글에서는 그 동안 3시/9시 또는 45도라고 양분하여 생각하였던 고정관념이 비롯된 원인을 밝히고 이를 벗어나 새로운 시각에서 바라볼 수 있는 계기가 되고자 한다.
푸쉬 방향에 대한 고정관념
전통적인 푸쉬의 방향은 45도 뒤쪽으로 미는 것이다. 그러나, 이런 개념을 뒤바꿔놓은 것은 살로몬의 ‘데스티네이션 스피드’ 비디오이다. 뿐만 아니라 [Liz Miller의 칼럼]을 보면 횡방향 푸쉬를 위해 심지어 2시/10시 방향으로 밀라고 설명한다.
그런데, 필라 월드팀의 클리닉은 지난 몇 년간 45도 뒤쪽으로 미는 ‘전통적인 방식’을 가르치고 있다. 게다가 최근 필라팀의 성적이 최고이기 때문에 더 혼란스럽기만 하다. 

그림2.1. 파워 박스, 그림2.2. 필라팀 클리닉(45도 방향 푸쉬)
(※그림2.2는 알팩닷컴의 [필라팀 클리닉 후기]에서 발췌했음을 밝힙니다)
또, 일부는 '푸쉬를 하는 동안 전진하기 때문에 45도 방향 처럼 보이지만 선수입장에서는 3시/9시를 만들려고 해야한다'라고 설명하기도 한다.
과연 어떤 것이 바람직한 것인지 함께 해답을 찾아보도록 하자.
푸쉬 방향과 추진력의 상관관계
어렵지 않은 물리적인 해석을 통해 푸쉬 방향에 따른 추진력에 대하여 살펴 보도록 하자. 먼저 푸쉬의 방향을 정의해보자.
일반적으로 말하는 푸쉬의 방향은 시계방향과 각도 두 가지를 이용 한다. 이 중에서 각도로 나타낼 때 푸쉬의 방향은 진행방향의 수직방향을 기준으로 표현한다(대각선 뒤쪽으로 미는 경우가 45도). 또한 프레임의 방향은 진행방향을 기준으로 말하는 게 일반적이다. 이러한 관례를 바탕으로 푸쉬의 방향에 영향을 주는 요소인 다리의 각도와 프레임의 각도를 정의하였다(그림2.3). ![]()
그림2.3. 다리의 각도와 프레임의 각도
해석을 쉽게 하기 위해 스케이트의 성질에 대하여 살펴보자. 스케이트는 프레임방향에 수직방향으로 작용하는 힘의 성분만이 추진력에 영향을 준다. 그림2.4는 서로 다른 크기의 힘이 작용하지만 같은 크기의 힘만 전달되는 것을 설명하고있다. 따라서, 힘의 손실을 최소로 하기 위해서는 프레임의 수직방향에 가깝게 힘을 가해야 한다. ![]()
그림2.4. 스케이트의 성질
따라서, 그림2.3에서 정의한 다리의 각도와 프레임의 각도는 비슷할수록 힘 전달 측면에서 유리하다. 이러한 특성을 바탕으로 계산의 편리를 위해 프레임과 다리의 각도가 같다고 가정하고자 한다(실제 주행에서도 큰 차이를 발생하지 않는다). 또한, 푸쉬의 방향을 다리의 각도로 표현하려 한다.
푸쉬에 의한 추진력은 뒤쪽으로 밀수록 커지며 측면으로 밀수록 작아진다. 그렇다면 소위 백 푸쉬가 바람직한 것일까? 이것은 정지상태에서 푸쉬를 하는 경우이며 속도가 빨라질수록 뒤쪽으로 미는 힘은 상쇄되고 옆으로 미는 힘만이 추진력으로 작용한다. 예를 들어 시속 30km/h로 달리면서 뒤로 푸쉬하려하면 헛발질을 하게 되는 이유는 다리를 뒤로 움직이는 속도보다 몸을 기준으로 지면이 움직이고 있는 속도가 더 빠르기 때문이다.
따라서, 속도가 빨라질수록 옆쪽으로 미는 것이(다리의 각도가 작은 것이) 효율적이 된다.
설명의 편의를 위해 뒤로 미는 힘이 완전히 상쇄 되는 속도를 ‘임계속도’라고 부르도록 하겠다.
(뒤로미는 힘이 완전히 상쇄된 후에도 옆으로 미는 힘에의한 가속이 가능하기 때문에 임계속도가 최대속도는 아니다) ![]()
그림2.5. 푸쉬방향에 따른 추진력과 속도에 의한 상쇄
다리를 움직일 수 있는 속도는 사람에 따라 다르기 때문에 정확히 시속 몇 킬로가 임계속도인지는 알 수 없다. 따라서,속도에서 최대 추진력을 발생하는 푸쉬의 방향은 그 순간의 주행 속도와 신체조건에 따라 달라진 다는 것이다.
속도의 변화(정지에서 임계속도까지)에 따라 최대 추진력을 발생시키는 푸쉬 방향의 변화는 다음과 같다. 속도가 빨라질 수록 효율적인 푸쉬각도가 작아지는 경향을 확인 할 수 있다. 또 지나치게 옆으로 미는 것 역시 효율적이지 않음을 알 수 있다. ![]()
그림2.6. 속도와 푸쉬 방향에 따른 추진력의 변화. ![]()
그림2.7. 최대 추진력을 발생시키는 푸쉬의 방향의 변화
위 결과에서는 정지상태에서 임계속도까지에 대해 효율적인 푸쉬 방향에 대하여 보여주고있다.
실제 주행시에는 이 임계속도보다 빠른 속도를 낼 수 있기 때문에 푸쉬각도는 더 작아질 것이다(그림2.7의 점선).
본 글에서는 이와 같이 속도에 따라 푸쉬의 각도가 작아지는 경향을 확인하는 데까지만 물리학적인 접근방법을 사용하고자 한다.
실제 주행의 푸쉬방향: 푸쉬 방향에 영향을 주는 또 다른 요인
서론에서 설명했듯이 푸쉬의 방향은 단순한 다리의 움직임이 아니라 여러 동작이 영향을 미쳐 만들어낸 결과이기 때문에 물리적으로 해석하는데는 한계를 갖고 있다.
실제 주행에서 푸쉬에 영향을 주는 다른 요인들을 살펴보자.
먼저 푸쉬를 시작해서 끝날 때까지 푸쉬의 방향은 변한다. 그림2.8은 지난 회에서 fall에 대해 멋진 시연을 해준 에디의 푸쉬 방향이다(동영상에서 추출한 결과). 0도에서 시작하여 25도까지 커졌다가 20도로 다시 줄어드는 것을 볼 수 있다. 마지막에 푸쉬각도가 다시 작아지는 것은 보다 긴 시간동안 푸쉬를 하기 위한 동작으로 ‘카빙(carving)’이라고 부르기도 한다. ![]()
그림2.8. 에디의 푸쉬 방향
다음으로 푸쉬가 끝나는 시점에서 반대쪽발을 내려놓는 셋다운 동작에 의한 영향도 생각할 수 있다. 상급자일수록 그리고 가속동작 일수록 셋다운 동작에 탄력을 주기 때문에 마지막 푸쉬각도가 커질 수 있다. 아래 파스칼의 셋다운 동작과 그 순간의 푸쉬에 대해 주의깊게 관찰해보기 바란다.(더블푸쉬 동작임을 고려하기 바람)
그림2.9. 파스칼의 주행 (살로몬, 데스티네이션 스피드 中)
파워 박스는 잘못된 이론인가?
실제 주행에서의 푸쉬 방향은 우리가 알고 있었던 파워박스이론과는 많이 다른 것을 알 수 있었다. 그렇다면 파워박스는 잘못된 이론인가? 이를 논하기 전에 먼저 파워박스가 무엇인지 확인해보자. 먼저 ‘데스티네이션 스피드’동영상에서 정의하는 파워박스의 의미는 다음과 같다.
“The Power Box is a zone around the body in which the skates can affect the push with maximum power”
번역하면 “파워박스는 스케이트가 최대의 힘으로 푸쉬에 영향을 미치는 몸 주위의 영역”을 말하는 것이다. 또한 “과학적 실험결과 푸쉬 힘이 가장 큰 순간은 파워박스 가운데 부근에 위치하며 휠 전체로 땅을 잡고 있는 순간”이라고 설명한다. 그림2.10의 검은색 명암이 푸쉬 힘을 나타내며 그중 가장 어두운 부분이 최대가 되는 순간이다.
그림2.10. 파워 박스(흰색)와 푸쉬 힘(검은색 명암) (살로몬, 데스티네이션 스피드 中)
즉, 파워박스는 푸쉬의 방향을 설명하기 위한 것이 아니라 푸쉬의 힘이 최대가 되는 순간을 설명하기 위한 것이며 이 순간은 모든 휠에 최대의 힘이 가해지는 순간이다. 그리고, 이러한 원리를 바탕으로 제안하는 연습방법이 ‘옆으로 밀기(lateral push)’동작이다. 다시말해 모든 휠로 푸쉬하는 연습을 하는 것이다.
결론적으로 파워박스 이론은 잘못된 것이 아니라 파워박스를 설명하는 화면과 그에 이어지는 연습방법 때문에 잘못 이해하고 있었던 것이다.
연습용 자세과 실제 자세를 혼동하는 일은 비단 파워 박스의 경우만은 아니다. 월드팀이 강습하는 내용을 이렇게 잘못 받아들이는 예가 많이 있다. 또 한가지 예가 리커버리에 관한 것인데 이것은 다음 편에서 설명하려 한다.
맺음말
지금까지 효율적인 푸쉬에 대하여 알아보았다.
정리해보면 효율적인 푸쉬방향이란 정해져있는 각도가 아니라 휠 전체를 이용해서 푸쉬하기 위한 방향이다.
반대로 말하면 휠 전체를 이용해서 푸쉬할 때 자연스럽게 나타나는 각도이기도 하다.
따라서, 속도에 관계없이 휠 전체를 이용해서 푸쉬할 수 있는 능력이 중요하며, 이를 위한 훈련방볍이 옆으로 밀기(lateral push)인 것이다.
스스로 제대로 푸쉬를 하고 있는지를 알고 싶다면 푸쉬동작에서 '무릎이 완전히 펴진 순간에 휠 5개가 모두 지면에 닿아있는지'를 확인해 보기 바란다. 또, 아래 파스칼의 푸쉬동작을 이러한 관점에서 살펴보기 바란다.
그림2.11. 파스칼의 푸쉬 동작 (살로몬, 데스티네이션 스피드 中)
지난 시간에 설명한 fall동작이 다소 혼동의 여지가 있었던 같다. ‘무게중심을 떨어뜨리는 동작이 중요하다’고 설명한 것이 ‘상체움직임이 큰 것이 좋다’라는 해석이 가능했던 것이다.
많은 초급자들이 fall에 대한 느낌을 이해하지 못하기 때문에 이해를 돕기 위한 설명이며 과도한 상체움직임은 당연히 바람직 하지 못하다.
이번 글에서 설명하고자 했던 내용 역시 추진력을 최대로 발생시키는 느낌을 이해할 수 있도록 도움이 되고자 한 글이다. 각도에 대한 고정관념을 버리자는 의미가 '아무렇게나 되는대로 밀자'라는 의미는 아님을 강조하면서 글을 마무리하려 한다.
'inline' 카테고리의 다른 글
| double push (0) | 2008.08.04 |
|---|---|
| Cross over (0) | 2008.08.04 |
| push(2) (0) | 2008.08.04 |
자바스크립트뿐만 아니라 다른 언어의 정규식 표현들은 항상 잊어 버리기 싶단 말이지...
항상 할때 마다 생각이 나지 않아서 정리해 본다.
-------------------------------------------------------------------------------
http://doc.ddart.net/scripting/html/reconintroductiontoregularexpressions.htm
http://www.javascriptkit.com/javatutors/redev2.shtml
http://del.icio.us/kebie/%EC%A0%95%EA%B7%9C%EC%8B%9D
CSS Hack에 대한 사설
http://www.javascriptkit.com/dhtmltutors/csshacks.shtml
--------------------------------------------------------------------------------------
1. 만들기
var re=/pattern/flags;
2)
var re=new RegExp("pattern","flags");
3) 차이 - new로 만들때에는 이스케이프문자는 \\는 \\\\로 해주어야 한다.
var re=/\\w/;
var re=new RegExp("\\\\w");
2. 플래그(flag)
- g (Global 찾기) 패턴에 맞는 모든문자 찾기
- i (Ignore Case) 대소문자 무시
- m (Multiline) 여러줄
3.
- ^ 문자열의 시작을 의미 ,m 플래그를 사용할경우 경우는 각 문자열의 시작
- $ 문자열의 끝을 의미 ,m 플래그를 사용할경우 경우는 각 문자열의 끝
- . 모든 한문자
4.
- [문자들] - 괄호안의 문자 하나와 매치
예) [abc] 는 a나 b나 c중 하나를 의미
- [^문자들] - 괄호안의 문자가 아닌문자와 매치
예) [^abc] 는 1,2.... d,e.... 등과 매치
- [문자1-문자2] - 문자1과 문자2와 그 사이의 값과 매치
예) [a-d] a,b,c,d와 매치
5. (abc) abc와 매치
6. |
예) (abc|def) abc나 def를 의미
7. *, +, ?
* 앞의 패턴이 0회 또는 그 이상반복됨
+ 앞의 패턴이 1회 또는 그 이상반복됨
? 앞의 패턴이 0또는 1회 반복
8. {n}, {n,}, {n,m} 패턴의 반복회수
예)
(abc){1,3} abc가 1에서 3회 반복
(abc){1} abc가 1회반복
(abc){,10} abc가 10회 이하 반복
9. 특수문자 (Escapes Character)
\\ 일반문자에 \\을 붙여서 특수한 용도로 사용한다.
\\f 폼피드(?)
\\r 캐리지리턴
\\n 새줄
\\t 일반 탭문자
\\v 세로 탭문자(?)
\\0 NUL널문자
[\\b] 백스페이스
\\s 공백문자
\\f, \\n, \\r, \\t, \\v, \\u00A0, \\u2028, \\u2029
\\S 공백이아닌문자
\\w 알파벳문자,숫자,_ [a-zA-Z0-9_]
\\W 알파벳문자,숫자,_가 아닌문자 [^a-zA-Z0-9_]).
\\d 정수(short for [0-9]).
\\D 정수가 아닌 문자 (short for [^0-9]).
\\b 단어의 경계 공백,새줄.
\\B 경계가 아닌문자.
\\cX 컨트롤+문자 E.g: \\cm matches control-M.
\\xhh 핵사코드
\\uhhhh 유니코드
예)
<script language="javascript">
function chk(pstr) {
var chkRep = /....-..-../;
alert(chkRep.test(pstr));
}
</script>
정규식은 다음과 같다.
(1) ^ (caret) : 라인의 처음이나 문자열의 처음을 표시
예 : ^aaa (문자열의 처음에 aaa를 포함하면 참, 그렇지 않으면 거짓)
(2) $ (dollar) : 라인의 끝이나 문자열의 끝을 표시
예 : aaa$ (문자열의 끝에 aaa를 포함하면 참, 그렇지 않으면 거짓)
(3) . (period) : 임의의 한 문자를 표시
예 : ^a.c (문자열의 처음에 abc, adc, aZc 등은 참, aa 는 거짓)
a..b$ (문자열의 끝에 aaab, abbb, azzb 등을 포함하면 참)
(4) [] (bracket) : 문자의 집합이나 범위를 나타냄, 두 문자 사이의 "-"는 범위를 나타냄
[]내에서 "^"이 선행되면 not을 나타냄
이외에도 "문자클래스"를 포함하는 [:문자클래스:]의 형태가 있다.
여기에서 "문자클래스"에는 alpha, blank, cntrl, digit, graph, lower, print, space, uppper, xdigit가 있다.
이에 대한 자세한 내용은 C언어의 [ctype.h]를 참조하면 된다.
예를 들어 [:digit:]는 [0-9]와 [:alpha:]는 [A-Za-z]와 동일하다.
이외에 [:<:]와 [:>:]는 어떤 단어(숫자, 알파벳, '_'로 구성됨)의 시작과 끝을 나타낸다.
예 : [abc] (a, b, c 중 어떤 문자, "[a-c]."과 동일)
[Yy] (Y 또는 y)
[A-Za-z0-9] (모든 알파벳과 숫자)
[-A-Z]. ("-"(hyphen)과 모든 대문자)
[^a-z] (소문자 이외의 문자)
[^0-9] (숫자 이외의 문자)
[[:digit:]] ([0-9]와 동일)
(5) {} (brace) : {} 내의 숫자는 직전의 선행문자가 나타나는 횟수 또는 범위를 나타냄
예 : a{3} ('a'의 3번 반복인 aaa만 해당됨)
a{3,} ('a'가 3번 이상 반복인 aaa, aaaa, aaaa, ... 등을 나타냄)
a{3,5} (aaa, aaaa, aaaaa 만 해당됨)
ab{2,3} (abb와 abbb 만 해당됨)
[0-9]{2} (두 자리 숫자)
doc[7-9]{2} (doc77, doc87, doc97 등이 해당)
[^Zz]{5} (Z와 z를 포함하지 않는 5개의 문자열, abcde, ttttt 등이 해당)
.{3,4}er ('er'앞에 세 개 또는 네 개의 문자를 포함하는 문자열이므로 Peter, mother 등이 해당)
(6) * (asterisk) : "*" 직전의 선행문자가 0번 또는 여러번 나타나는 문자열
예 : ab*c ('b'를 0번 또는 여러번 포함하므로 ac, ackdddd, abc, abbc, abbbbbbbc 등)
* (선행문자가 없는 경우이므로 임의의 문자열 및 공백 문자열도 해당됨)
.* (선행문자가 "."이므로 하나 이상의 문자를 포함하는 문자열, 공백 문자열은 안됨)
ab* ('b'를 0번 또는 여러번 포함하므로 a, accc, abb, abbbbbbb 등)
a* ('a'를 0번 또는 여러번 포함하므로 k, kdd, sdfrrt, a, aaaa, abb, 공백문자열 등) doc[7-9]* (doc7, doc777, doc778989, doc 등이 해당)
[A-Z].* (대문자로만 이루어진 문자열)
like.* (직전의 선행문자가 '.'이므로 like에 0 또는 하나 이상의 문자가 추가된 문자열이됨, like, likely, liker, likelihood 등)
(7) + (asterisk) : "+" 직전의 선행문자가 1번 이상 나타나는 문자열
예 : ab+c ('b'를 1번 또는 여러번 포함하므로 abc, abckdddd, abbc, abbbbbbbc 등, ac는 안됨)
ab+ ('b'를 1번 또는 여러번 포함하므로 ab, abccc, abb, abbbbbbb 등)
like.+ (직전의 선행문자가 '.'이므로 like에 하나 이상의 문자가 추가된 문자열이 됨, likely, liker, likelihood 등, 그러나 like는 해당안됨)
[A-Z]+ (대문자로만 이루어진 문자열)
(8) ? (asterisk) : "?" 직전의 선행문자가 0번 또는 1번 나타나는 문자열
예 : ab?c ('b'를 0번 또는 1번 포함하므로 abc, abcd 만 해당됨)
(9) () (parenthesis) : ()는 정규식내에서 패턴을 그룹화 할 때 사용
(10) | (bar) : or를 나타냄
예 : a|b|c (a, b, c 중 하나, 즉 [a-c]와 동일함)
yes|Yes (yes나 Yes 중 하나, [yY]es와 동일함)
korea|japan|chinese (korea, japan, chinese 중 하나)
(11) \\ (backslash) : 위에서 사용된 특수 문자들을 정규식내에서 문자를 취급하고 싶을 때 '\\'를 선행시켜서 사용하면됨
예 : filename\\.ext ("filename.ext"를 나타냄)
[\\?\\[\\\\\\]] ('?', '[', '\\', ']' 중 하나)
정규식에서는 위에서 언급한 특수 문자를 제외한 나머지 문자들은 일반 문자로 취급함
-----------------------------------------------------------------------------------------------
| 문자 | 설명 |
|---|---|
| \\ | 그 다음 문자를 특수 문자, 리터럴, 역참조, 또는 8진수 이스케이프로 표시합니다. 예를 들어, 'n'은 문자 "n"을 찾고 '\\n'은 줄 바꿈 문자를 찾습니다. '\\\\' 시퀀스는 "\\"를 찾고 '\\('는 "("를 찾습니다. |
| ^ | 입력 문자열의 시작 위치를 찾습니다. Multiline 속성이 설정되어 있으면 ^는 '\\n' 또는 '\\r'앞의 위치를 찾습니다. |
| $ | 입력 문자열의 끝 위치를 찾습니다. Multiline 속성이 설정되어 있으면 $는 '\\n' 또는 '\\r'뒤의 위치를 찾습니다. |
| * | 부분식의 선행 문자를 0개 이상 찾습니다. 예를 들어, 'zo*'는 "z", "zoo" 등입니다. *는 {0,}와 같습니다. |
| + | 부분식의 선행 문자를 한 개 이상 찾습니다. 예를 들어, 'zo+'는 "zo", "zoo" 등이지만 "z"는 아닙니다. +는 {1,}와 같습니다. |
| ? | 부분식의 선행 문자를 0개 또는 한 개 찾습니다. 예를 들어, "do(es)?"는 "do" 또는 "does"의 "do"를 찾습니다. ?는 {0,1}과 같습니다. |
| {n} | n은 음이 아닌 정수입니다. 정확히 n개 찾습니다. 예를 들어, 'o{2}'는 "Bob"의 "o"는 찾지 않지만 "food"의 o 두 개는 찾습니다. |
| {n,} | n은 음이 아닌 정수입니다. 정확히 n개 찾습니다. 예를 들어, 'o{2}'는 "Bob"의 "o"는 찾지 않지만 "foooood"의 모든 o는 찾습니다. 'o{1,}'는 "o+"와 같고, 'o{0,}'는 "o*"와 같습니다. |
| {n,m} | m과 n은 음이 아닌 정수입니다. 여기서 m은 n보다 크거나 같습니다. 최소 n개, 최대 m개 찾습니다. 예를 들어, "o{1,3}"은 "fooooood"의 처음 세 개의 o를 찾습니다. "o{0,1}"은 "o?"와 같습니다. 쉼표와 숫자 사이에는 공백을 넣을 수 없습니다. |
| ? | 이 문자가 다른 한정 부호(*, +, ?, {n}, {n,}, {n,m}) 의 바로 뒤에 나올 경우 일치 패턴은 제한적입니다. 기본값인 무제한 패턴은 가능한 많은 문자열을 찾는 데 반해 제한적인 패턴은 가능한 적은 문자열을 찾습니다. 예를 들어, "oooo" 문자열에서 "o+?"는 "o" 한 개만 찾고, "o+"는 모든 "o"를 찾습니다. |
| . | "\\n"을 제외한 모든 단일 문자를 찾습니다. "\\n"을 포함한 모든 문자를 찾으려면 '[.\\n]' 패턴을 사용하십시오. |
| (pattern) | pattern을 찾아 검색한 문자열을 캡처합니다. 캡처한 문자열은 VBScript의 경우 SubMatches 컬렉션, Jscript의 경우 $0...$9 속성을 이용하여 결과로 나오는 Matches 컬렉션에서 추출할 수 있습니다. 괄호 문자인 ( )를 찾으려면 "\\(" 또는 "\\)"를 사용하십시오. |
| (?:pattern) | pattern을 찾지만 검색한 문자열을 캡처하지 않습니다. 즉, 검색한 문자열을 나중에 사용할 수 있도록 저장하지 않는 비캡처 검색입니다. 이것은 패턴의 일부를 "or" 문자(|)로 묶을 때 유용합니다. 예를 들어, 'industr(?:y|ies)는 'industry|industries'보다 더 경제적인 식입니다. |
| (?=pattern) | 포함 예상 검색은 pattern과 일치하는 문자열이 시작하는 위치에서 검색할 문자열을 찾습니다. 이것은 검색한 문자열을 나중에 사용할 수 있도록 캡처하지 않는 비캡처 검색입니다. 예를 들어, "Windows(?=95|98|NT|2000)"는 "Windows 2000"의 "Windows"는 찾지만 "Windows 3.1"의 "Windows"는 찾지 않습니다. 예상 검색은 검색할 문자열을 찾은 후 예상 검색 문자열을 구성하는 문자 다음부터가 아니라 마지막으로 검색한 문자열 바로 다음부터 찾기 시작합니다. |
| (?!pattern) | 제외 예상 검색은 pattern과 일치하지 않는 문자열이 시작하는 위치에서 검색할 문자열을 찾습니다. 이것은 검색한 문자열을 나중에 사용할 수 있도록 캡처하지 않는 비캡처 검색입니다. 예를 들어, "Windows(?!95|98|NT|2000)"는 "Windows 3.1"의 "Windows"는 찾지만 "Windows 2000"의 "Windows"는 찾지 않습니다. 예상 검색은 검색할 문자열을 찾은 후 예상 검색 문자열을 구성하는 문자 다음부터가 아니라 마지막으로 검색한 문자열 바로 다음부터 찾기 시작합니다. |
| x|y | x 또는 y를 찾습니다. 예를 들어, "z|food"는 "z" 또는 "food"를 찾습니다. "(z|f)ood"는 "zood" 또는 "food"를 찾습니다. |
| [xyz] | 문자 집합입니다. 괄호 안의 문자 중 하나를 찾습니다. 예를 들어, "[abc]"는 "plain"의 "a"를 찾습니다. |
| [^xyz] | 제외 문자 집합입니다. 괄호 밖의 문자 중 하나를 찾습니다. 예를 들어, "[^abc]"는 "plain"의 "p"를 찾습니다. |
| [a-z] | 문자 범위입니다. 지정한 범위 안의 문자를 찾습니다. 예를 들어, "[a-z]"는 "a"부터 "z" 사이의 모든 소문자를 찾습니다. |
| [^a-z] | 제외 문자 범위입니다. 지정된 범위 밖의 문자를 찾습니다. 예를 들어, "[^a-z]"는 "a"부터 "z" 사이에 없는 모든 문자를 찾습니다. |
| \\b | 단어의 경계, 즉 단어와 공백 사이의 위치를 찾습니다. 예를 들어, "er\\b"는 "never"의 "er"는 찾지만 "verb"의 "er"는 찾지 않습니다. |
| \\B | 단어의 비경계를 찾습니다. "er\\B"는 "verb"의 "er"는 찾지만 "never"의 "er"는 찾지 않습니다. |
| \\cx | X 가 나타내는 제어 문자를 찾습니다. 예를 들어, \\cM은 Control-M 즉, 캐리지 리턴 문자를 찾습니다. x 값은 A-Z 또는 a-z의 범위 안에 있어야 합니다. 그렇지 않으면 c는 리터럴 "c" 문자로 간주됩니다. |
| \\d | 숫자 문자를 찾습니다. [0-9]와 같습니다. |
| \\D | 비숫자 문자를 찾습니다. [^0-9]와 같습니다. |
| \\f | 폼피드 문자를 찾습니다. \\x0c와 \\cL과 같습니다. |
| \\n | 줄 바꿈 문자를 찾습니다. \\x0a와 \\cJ와 같습니다. |
| \\r | 캐리지 리턴 문자를 찾습니다. \\x0d와 \\cM과 같습니다. |
| \\s | 공백, 탭, 폼피드 등의 공백을 찾습니다. "[ \\f\\n\\r\\t\\v]"와 같습니다. |
| \\S | 공백이 아닌 문자를 찾습니다. "[^ \\f\\n\\r\\t\\v]"와 같습니다. |
| \\t | 탭 문자를 찾습니다. \\x09와 \\cI와 같습니다. |
| \\v | 수직 탭 문자를 찾습니다. \\x0b와 \\cK와 같습니다. |
| \\w | 밑줄을 포함한 모든 단어 문자를 찾습니다. "[A-Za-z0-9_]"와 같습니다. |
| \\W | 모든 비단어 문자를 찾습니다. "[^A-Za-z0-9_]"와 같습니다. |
| \\xn | n을 찾습니다. 여기서 n은 16진수 이스케이프 값입니다. 16진수 이스케이프 값은 정확히 두 자리여야 합니다. 예를 들어, '\\x41'은 "A"를 찾고 '\\x041'은 '\\x04'와 "1"과 같습니다. 정규식에서 ASCII 코드를 사용할 수 있습니다. |
| \\num | num을 찾습니다. 여기서 num은 양의 정수입니다. 캡처한 문자열에 대한 역참조입니다. 예를 들어, '(.)\\1'은 연속적으로 나오는 동일한 문자 두 개를 찾습니다. |
| \\n | 8진수 이스케이프 값이나 역참조를 나타냅니다. \\n 앞에 최소한 n개의 캡처된 부분식이 나왔다면 n은 역참조입니다. 그렇지 않은 경우 n이 0에서 7 사이의 8진수이면 n은 8진수 이스케이프 값입니다. |
| \\nm | 8진수 이스케이프 값이나 역참조를 나타냅니다. \\nm 앞에 최소한 nm개의 캡처된 부분식이 나왔다면 nm은 역참조입니다. \\nm 앞에 최소한 n개의 캡처가 나왔다면 n은 역참조이고 뒤에는 리터럴 m이 옵니다. 이 두 경우가 아닐 때 n과 m이 0에서 7 사이의 8진수이면 \\nm은 8진수 이스케이프 값 nm을 찾습니다. |
| \\nml | n이 0에서 3 사이의 8진수이고 m과 l이 0에서 7 사이의 8진수면 8진수 이스케이프 값 nml을 찾습니다. |
| \\un | n은 4 자리의 16진수로 표현된 유니코드 문자입니다. 예를 들어, \\u00A9는 저작권 기호(©)를 찾습니다. |
http://msdn.microsoft.com:80/scripting/default.htm다음 정규식은 그 기능을 제공합니다. JScript의 경우는 다음과 같습니다.
/(\\w+):\\/\\/([^/:]+)(:\\d*)?([^# ]*)/VBScript의 경우는 다음과 같습니다.
"(\\w+):\\/\\/([^/:]+)(:\\d*)?([^# ]*)"괄호로 묶은 첫 번째 부분식은 웹 주소의 프로토콜 부분을 캡처하도록 설계되었습니다. 이 부분식은 콜론과 두 개의 슬래시 앞에 오는 단어를 모두 찾습니다. 괄호로 묶은 두 번째 부분식은 주소 중 도메인 주소 부분을 캡처합니다. 이 부분식은 '^', '/' 또는 ':' 문자를 포함하지 않는 문자 시퀀스를 찾습니다. 괄호로 묶은 세 번째 부분식은 웹 사이트 포트 번호가 지정되어 있으면 이를 캡처합니다. 이 부분식은 콜론 다음에 오는 0 이상의 자리 수를 찾습니다. 그리고 마지막으로 괄호로 묶은 네 번째 부분식은 웹 주소로 지정된 경로 및/또는 페이지 정보를 캡처합니다. 이 부분식은 '#' 또는 공백 문자를 제외한 하나 이상의 문자를 찾습니다.
정규식을 위의 URI에 적용하면 부분 검색 문자열에 다음이 포함됩니다.
RegExp.$1은 "http"를 포함합니다.
RegExp.$2는 "msdn.microsoft.com"을 포함합니다.
RegExp.$3은 ":80"을 포함합니다.
RegExp.$4는 "/scripting/default.htm"을 포함합니다.
1. 프로퍼티(클래스필드) 정의하기.
class_name = function ( parameter, ... ) {
....
property declaration...
...
}
또는
function class_name ( parameter, ... ) {
....
property declaration...
...
}
function 이 함수를 의미하는 것이 아니라 여기서는 클래스 선언을 위해서 사용하는 키워드임. 단어 자체가 주는 사전적 의미에 함몰되어서 자꾸 딴지 걸면 안됨.(내가 ... 그랬었음..). 클래스나 함수나 어차피 프로세스로 존재할때 메모리를 차지하는 모듈로서 본다면 객체와 메소드 따위의 구분이 의미가 없다.
public class Student {
String name;
int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
}
위와같은 자바 클래스에 대응하는 자바스크립트의 클래스는 다음과 같음.
Student = function(name, age) {
this.name = name;
this.age = age;
} // 초간단. -_-;
다음과 같이 인스턴스를 생성하고 사용할 수 있음.
Student student = new Student("전지현", 26);
document.write("이름 : " + student.name + ", 나이 : " + student.age );
2. 메소드 정의하기.
메소드도 정의할 수 있는데 두가지 방법이 있음. prototype에 정의하는 방법과 클래스 자체에 정의하는 방법.
2-1. prototype 프로퍼티에 메소드 정의
위에서 만든 Student 클래스에 getter/setter 메소드를 정의하면 다음과 같다.
Student.prototype.getName = function() {
return this.name;
}
Studoent.prototype.setName = function (name) {
this.name = name;
}
이제 다음은 동일한 결과를 보여준다.
student.name;| student.getName();
student.name = "왕지현"; | student.setName("왕지현");
위에서 주의할 점은 Student.prototype.getName() 이 아니라 그냥 getName임. 괄호 넣으면 작동하지 않음. -_-a
여기서 잠깐 prototype 에대해서 짚고 넘어가보자.
자바에서 일반적인 객체 상속구조를 떠올려보자.
student.getAddress();
라고 호출하면 Student 클래스에서 아직 정의되어 있지 않기 때문에 부모 클래스에서 getAddress() 메소드가 있는지 찾는다. 존재 하지 않으면 그 부모클래스의 부모 클래스를 조회하고 마지막으로 Object 객체까지 거슬러 올라가서 최종적으로 찾지 못하면 예외가 발생한다.
javascript에서 정의되는 class는 모두 prototype이라는 프로퍼티를 가지는데 객체에 존재하지 않는 메소드나 클래스 필드를 호출하면 prototype 프로퍼티에서 메소드나 클래스 필드를 찾는다. prototype에서 찾지 못하면 prototype의 prototype 프로퍼티까지 계속해서 탐색을 하고 최종적으로 찾지 못하면
"undefined"(클래스 필드인 경우) , ""(메소드인 경우)
를 출력한다. 위에서 메소드를 정의한 방식이 바로 이 prototype 프로퍼티에 메소드를 정의한 것인데 엄밀히 말하면 위에서 정의한 메소드는 Student 클래스의 것이 아닌, prototype 프로퍼티의 메소드인 셈이다. 하지만 사용하는 입장에서는 중요한 내용은 아닌 듯.
기억해야 할 점은 prototype 프로퍼티는 인스턴스당 할당되는 것이 아니라, 클래스당 하나씩 할당된다는 것. 마치 자바에서 Object.class, ArrayList.class 와 같은 Class 를 떠올리면 좋을듯 하다.
student.getEmail() 을 호출하면 정의되지 않은 메소드이므로 TypeError가 발생하고 진행중인 메소드가 종료된다. 아무것도 출력이 안되는 것처럼 보이지만 예외가 던져져서 진행중이던 메소드를 벗어나버리는 것임.
Student jenny = new Student(....);
try {
jenny.getEmail(); // NO!!!
} catch(e) {
alert(e); // firefox에서는 예외가 던져짐.
}
Student.prototype.getEmail = function() { return googler@gmail.com; };
jenny.getEmail() ; // OK!!!!!!!!!!!
위처럼 prototype에 메소드를 정의하면 메소드를 정의하기 이전에 생성되어 사용되던 인스턴스라도 getEmail() 메소드를 사용할 수 있게 된다. 왜냐하면 위에서 말했듯이 prototype은 클래스당 하나이므로 하나의 클래스에서 생성된 인스턴스들은 prototype을 공유한다.
이때문에 언제든지 메소드나 클래스 필드를 마음대로 만들어낼 수 있으니 조낸! 탄력적이다!!
2-2. 클래스 자체에 메소드 정의
prototype 이 아닌 class 자체에 메소드를 생성하는 방법도 있다.
Student = function(name, age) {
this.name = name;
this.age = age;
this.getName = function() { return this.name ; }
this.setName = function(name) { this.name = name;}
} // 초간단. -_-;
그렇다면 메소드를 prototype에 정의하는 것과 클래스 자체에 정의하는게 어떻게 다를까?
클래스 자체에 정의할 경우, 클래스의 인스턴스를 여러개 생성할 때 메소드 코드를 인스턴스들마다 따로 갖게 된다. 하지만 prototype에 메소드를 정의하면 동일한 클래스로부터 생성된 인스턴스들은 하나의 prototype 프로퍼티를 공유하므로 인스턴스들마다 중복해서 메소드 코드를 가질 필요가 없게된다.
따라서 자바스크립트에서 클래스를 생성할 때 가능하면 prototype에 메소드를 정의하는게 메모리를 아낄 수 있는 길이다...라고 일단 정리하게 넘어가겠다. (그런데 메소드를 클래스 자체에 정의해야 하는 상황도 있지 않을까? 잠깐 고민해봤는데, 아직은 없는 것 같다. 인스턴스의 상태는 프로퍼티에 좌우되기 때문에 메소드를 인스턴스마다 따로 가져야할 상황은 없는 듯.)
하지만 다음과 같이 오버하면 안된다.
Student = function(name, age) {
Student.prototype.name = name;
Student.prototype.age = age;
}
이렇게 하면 클래스의 인스턴스들이 모두 동일한 이름과 나이를 갖게 된다. 즉,
Student jane = new Student("jane", 21);
을 생성한 후
Student jack = new Student("jack", 34);
로 jack을 생성하면 jane의 이름이 "jack", 나이가 34살로 둔갑한다.(뜨아~).
정리하면 상황에 맞게 잘 사용해야 한다는 것이다.
2-3 효율적인 클래스 정의 방법
2-1 방식의 문제점은 클래스를 정의할 때 코드가 난잡해져서 가독성이 떨어진다는 점이다. 클래스를 여러개 정의하는 상황이라면 메소드를 정의한 블록들이 산재해 있어서 클래스의 모습이 눈에 딱 들어오지는 않는다.
반면에 2-2는 코드가 깔끔해져서 가독성이 높아지지만 문제는 위에서 말했듯이 인스턴스들이 중복된 메소드 코드를 갖는다는 점이다.(간단한 클래스라면 상관없겠지만...)
그래서 생각해낸 방법은 다음과 같다.
function Student(name, age)
{
var strName = name;
var intAge = age;
Student.prototype.getName() { return this.strName; }
Student.prototype.setName(name) { this.strName = name; }
Student.prototype.getAge() { return this.strAge; }
Student.prototype.setAge(age) { this.intAge = age; }
}
메소드 정의부를 클래스 내로 옮기면서
fucntion class_name ( parameter, ... )
{
class_name.prototype.method_name ( parameter, ... ) { ... };
.....
}
로 바꿔주는 것. IE와 FF 에서 테스트해봤는데 아무 문제없이 잘 돌아간다. 흐화화~
3. JSON 표기법을 이용한 클래스 정의
아, 이런것도 있다. JSON에 대한 자세한 내용은 http://www.json.org/ 에서 보면 될 것 같다.
위에서 메소드 정의하는 부분을 아래의 코드로 표현했다.
Student.prototype.getName = function() {
return this.name;
}
Studoent.prototype.setName = function (name) {
this.name = name;
}
위의 코드를 JSON 을 이용해서 나타내면 다음과 같다.
Student.prototype = {
getName : function() {
return this.name;
}
setName : function (name) {
this.name = name;
}
}
4. 정보은닉(encapsulation)
위에서 설명한 클래스 정의 방법은 정보은닉이 안된다는 문제점이 있다. student.name 으로 프로퍼티에 접속이 가능한데 OOP 에서는 이런 접근을 꺼리기 때문에 자바스크립트에서도 이걸 흉내내려는 시도가 있지 않았나 추측해본다.
여자들의 몸무게 평균을 내는 저울이 있다고 치자. 몇 명의 여성의 정보를 가져와서 전체 몸무게을 내는데 여자들은 자신의 몸무게가 드러나는 것을 반대한다. 저울을 통해서 특정 여성의 몸무게를 알아서는 안되는 경우를 생각해보자.
이런 상황을 모델링하면 다음과 같다.
function Scale ( ) {
this.womans = [new Woman(...), new Woman(...), ...];
this.prototype.getTotalWeights() {
var totalWeight = 0;
for( i = 0 ; i < womans.length ; i++) {
totlaWeight += this.womans[i].getWeight();
}
return totalWeight;
}
}
.....
Scale scale = new Scale() ;
scale.getTotalWeight();
위코드에서는
scale.womans[0].getWeight();
로 특정 여성의 몸무게에 접근할 수 있다.
정보은닉이란 외부에 노출되어서는 안되는 데이터를 꼭꼭 감추는 것을 의미하는데 여기서 여성들의 몸무게 노출을 막기 위해서는 다음과 같이 프로퍼티 선언을 변경해준다.
function Scale ( ) {
var womans = [new Woman(....), new Woman(....), new Woman(...)];
this.prototype.getTotalWeights() {
var totalWeight = 0;
for( i = 0 ; i < womans.length ; i++) {
totlaWeight += womans[i].getWeight();
}
return totalWeight;
}
}
이제 scale.womans 로 접근하면 "undefined"가 출력되기 때문에 여성들 개개인의 몸무게를 보여주는 메소드 호출을 할 수 없다.
5. 정리하면.
자바스크립트에서 클래스를 정의해서 사용하는게 불필요하고 이상해 보일 수도 있다. 왜냐하면 지금까지 이렇게 하지 않아도 자바스크립트를 잘만 써왔기 때문이다. 이런 편견은 예전에 자바스크립트가 화면을 동적으로 구성하는 도구로서 사용되어왔기 때문에 생긴 것이 아닌가 싶다. 또한 언어가 매우 탄력성이 높아서 초기에 자바스크립트를 어떠한 체계에 맞춰서 사용할지 뚜렷한 가이드라인이 없었기 때문이기도 하다.
하지만 ajax의 도입으로 자바스크립트가 데이터 처리를 위한 수단으로서 많이 사용되고 있다. 서버쪽에서는 데이터 처리만 해서 클라이언트에 전달해주고 클라이언트는 ajax 를 이용해서 데이터를 2차 가공한 후 display하는 ui 과정을 모두 떠안게 되는 것이다.
이러한 변화에 대응하기 위해서 자바스크립트도 class 를 도입해서 좀 더 체계적으로 코드를 만들어어지 향후 유지 보수하는데 어려움이 없을 것으로 생각된다. 예전에는 자바스크립트를 아주 우스운 언어, 웹 디자이너들이나 다루는 수준낮은 언어로 생각해왔지만 이제는 생각을 바꿀 때가 된 것 같다.
OOP의 개념을 자바스크립트에 이식해서 언어의 질을 한층 높일 때가 되지 않았나 싶다.
데이터 모델 정규화/반정규화의 실전 프로젝트 적용
정규화를 잘 이해하여 데이터 모델링을 해야 하는 프로젝트 모델러가 이를 정확하게 이해하지 못하는 경우가 종종 있다. 검증되어 있고 체계화된 이론적 기반 위에 데이터베이스라는 기초를 건축하지 않으면 그 데이터베이스는 모래 위에 세운 집처럼 금방 무너지고 말 것이다. 정규화의 이론은 건축물의 기초공사를 해야 하는 사상에 해당한다. 그저 어렴풋이, 알듯 모를듯 희미한 기억의 지식으로 튼튼하고 견고한 데이터 모델을 만들어 낼 수 없다.
“붕어빵에 붕어가 없다!”고 한다. 데이터 모델링을 학교나 학원에서 배운 사람이나 시스템 구축 프로젝트에서 데이터 모델링을 경험한 사람치고 정규화에 대한 이야기를 듣거나 이야기하지 않은 사람은 없을 것이다. 그만큼 정규화의 이론은 데이터를 분석하여 데이터 모델로 만들고 그것을 다시 데이터베이스화하는 이론의 뿌리가 되는 중요한 것이다. 그러나 붕어빵에 붕어가 없듯이 정규화에 대한 언급은 누구나 하지만 정규화에 대한 내용을 정확하게 이해하고 실전에 적용할 수 있는 사람은 의외로 극히 드물다는 사실을 즉시해야 하고 사태의 심각성을 인식할 필요가 있다.
정규화에 관련된 이론을 배운다고 하면 대부분 과목, 수강신청, 교수 등 항상 정해진 샘플 사례에 표시 방법도 과목코드->과목명과 같이 설명되어 실전 프로젝트에서 사용하는 표기법(notation)과 동 떨어져 있다. 따라서 학습할 때는 개념적으로 이해한다고 하더라도 혹은 적어도 시험문제가 출제되면 100점은 맞는다고 하더라도, 실전 프로젝트에서는 무엇을 어떻게 왜 그렇게 해야 하는지 도무지 이해하지 못하는 경우가 대부분이다. 잘 정리된 이론은 실세계에서 응용되어 다른 창조물을 도출할 수 있을 때 비로소 지식가치의 효용이 있다. 하지만 불행히도 정규화의 이론은 그 내용이 너무 훌륭함에도 불구하고 실전에 반영하는 방법을 정확하게 알지 못해 그의 가치를 제대로 적용하지 못하는 경우가 자주 나타나는 것이다. 이제 우리의 눈을 희미하게 하는 이론의 틀을 깨고 개념을 명확하게 하여 실전에서 곧 바로 적용할 수 있는 참된 지식가치로 정규화의 이론을 활용해 보자.
정규화 규칙은 어디에 쓰는 물건인가?
“그런데 실전 프로젝트에서는 정규화를 적용한 적이 없습니다!”라고 반문하는 독자도 있을 것이다. 맞는 이야기이다. 프로젝트에서는 정규화라고 하는 태스크(task)로 일을 진행하지는 않는다. 다만, 프로젝트에서 데이터 모델링을 할 때는 논리 모델->물리 모델 2단계로 수행하거나 개념 모델->논리 모델->물리 모델 3단계 또는 객체지향 분석설계에서는 클래스 다이어그램->OR(객체-관계형) 맵핑->물리 모델로 하거나 업무가 익숙하고 시스템의 규모가 작은 경우 곧 바로 물리적인 데이터 모델링을 하는 경우로 진행한다. “그렇다면 데이터베이스에서 그렇게 중요하다고 하는 정규화 방법은 활용되지 않는가?”라고 반문할 수 있다.
정규화 규칙은 실제 프로젝트에서 두 가지 성격으로 중요하게 반영이 된다.
첫 번째는 엔티티 타입을 오브젝트 분석 방법에 의해 도출할지라도 분석 방법의 배경에는 이미 중복 제거 및 주식별자에 의한 종속과 속성에 의한 종속 등 제3정규화 규칙이 모델링 작업의 기초에 관여한다고 봐도 된다. 즉 숙련된 데이터 모델러는 이미 정규화에 대한 개념이 확보된 상태에서 각각의 오브젝트를 엔티티 타입으로 선정하며 새로운 엔티티 타입으로 분리될 때도 각 속성의 집합 개념과 종속성의 개념을 적용하여 분리시켜 나간다.
두 번째는 정규화 방법을 프로젝트에서 적절하게 활용하기 위해서는 오브젝트별로 엔티티 타입을 분석해가면서 각각의 오브젝트가 적절하게 도출이 되었는지 또는 더 분리되어야 해야 하는지를 정규화 규칙에 대입하며 검증하는 것이다. 또한 단계별로 작업이 수행된 이후에 정규화 규칙에 의해 모든 엔티티 타입에 대해서 검증하는 작업이 필요하고 이상이 있는 경우에는 정규화 규칙을 적용하여 엔티티 타입을 정제해 나가도록 한다.
정규화의 의미
그러면, 데이터 모델링에서 정규화는 무엇을 의미하는가? 1970년 6월 E.F Code 박사는 ‘대규모 데이터 저장을 위한 관계형 데이터 모델(A Relational Model of Data for Large Shared Databanks)’이라는 연구에서 새로운 관계형 모델을 발표했다. 수학자인 Code 박사에 의해 제안된 정규화의 이론은 실세계에서 발생하는 데이터들을 수학적인 방법에 의해 구조화시켜 체계적으로 데이터를 관리할 수 있도록 하였다. 처음에는 1차 정규화, 2차 정규화, 3차 정규화가 제시되었으나 이후에 보이스-코드 정규화가 제시되었고, 이후 4차 정규화, 5차 정규화의 이론이 발표되었다.
정규화(normalization)란 다양한 유형의 데이터 값 검사를 통해 데이터 모델을 더 구조화시키고 개선시켜 나가는 절차에 관련된 이론이다. 정규화가 프로세스를 나타내는 의미라면 정규형(normalform)은 정규화가 완성된 이후의 엔티티 타입(테이블)을 지칭하는 용어이다. 정규화를 이해하기 위해서는 이론적인 기반이 되는 함수 종속성을 이해할 필요가 있다. 함수의 종속성(functional dependency)은 데이터들이 어떤 기준 값에 의해 종속되는 현상을 지칭하는 것이다. 이 때 기준 값을 결정자(determinant)라 하고 종속되는 값을 종속자/의존자(dependent)라고 한다.
<그림 1> 함수의 종속성

<그림 1>을 보면 사람이라는 엔티티 타입에는 주민등록번호, 이름, 출생지, 호주라는 속성이 존재한다. 여기에서 이름, 출생지, 호주라는 속성은 주민등록번호 속성에 종속된다. 만약 어떤 사람의 주민등록번호가 신고되면 그 사람의 이름, 출생지, 호주가 생성되어 단지 하나의 값만을 가지게 된다. 이를 기호로 표시하면 다음과 같다.
주민등록번호 -> (이름, 출생지, 호주)
즉 ‘주민등록번호가 이름, 출생지, 호주를 함수적으로 결정한다’라고 말할 수 있다. 실세계의 데이터들은 대부분 이러한 함수 종속성을 가지고 있다. 함수의 종속성은 데이터가 가지고 있는 근본적인 속성으로 인식되고 있다. 정규화의 궁극적인 목적은 반복적인 데이터를 분리하고 각 데이터가 종속된 테이블에 적절하게(프로세스에 의해 데이터의 정합성이 지켜질 수 있어야 함) 배치되도록 하는 것이므로 이 함수의 종속성을 이용하여 정규화 작업이나 각 오브젝트에 속성을 배치하는 작업을 한다.
• 정규화는 적절한 엔티티 타입에 각각의 속성들을 배치하고 엔티티 타입을 충분히 도출해가는 단계적인 분석 방법이다.
• 정규화 기술은 엔티티 타입에 속성들이 상호 종속적인 관계를 갖는 것을 배경으로 종속 관계를 이용하여 엔티티 타입을 정제하는 방법이다.
• 각각의 속성들이 데이터 모델에 포함될 수 있는 정규화의 원리를 이용하여 데이터를 분석하는 방법에서 활용될 수 있다.
• 정규화는 현재 데이터를 검증할 수 있고 엔티티 타입을 데이터가 표현하는 관점에서 정의하는데 이용할 수 있다.
• 정규화는 엔티티 타입을 분석하는 관점이 오브젝트별 분석하는 방법이 아닌 개별 데이터를 이용한 수학적인 접근방법을 통해 분석하는 방법이다.
정규화에 대한 실전 프로젝트 적용 사례
<표 1>은 1차 정규화, 2차 정규화, 3차 정규화와 보이스-코드정규화 그리고 4차와 5차 정규화에 대한 정리이다. 정규화의 정의를 이용하여 실전 프로젝트에서는 어떻게 적용할 수 있는지 살펴보자.
<표 1> 정규화에 대한 정리
| 정규화 | 정규화 내용 |
| 1차 정규화 | 복수의 속성 값을 갖는 속성을 분리 |
| 2차 정규화 | 주식별자에 종속적이지 않은 속성의 분리 부분 종속 속성을 분리 |
| 3차 정규화 | 속성에 종속적인 속성의 분리 이전 종속 속성의 분리 |
| 보이스-코드 정규화 | 다수의 주식별자 분리 |
| 4차 정규화 | 다가 종속 속성 분리 |
| 5차 정규화 | 결합 종속일 경우는 두 개 이상의 N개로 분리 |
1차 정규화(복수의 속성 값을 갖는 속성의 분리)
1차 정규화(first normalization)는 복수의 속성 값을 가진 속성을 분리한다. 즉 테이블 하나의 컬럼에는 여러 개의 데이터 값이 중복되어 나타나지 않아야 한다는 것이다. 이는 각 속성에 값이 반복 집단이 없는 원자 값(atomic value)으로만 구성되어 있어야 한다는 것을 의미한다. 이를 다시 정의하면, “모든 엔티티 타입의 속성에는 하나의 속성 값만을 가지고 있어야 하며 반복되는 속성 값의 집단은 별도의 엔티티 타입으로 분리한다”로 정의할 수 있다. 이 때 전제조건은 결정자에 의존하는 의존자의 반복성을 나타낸다. 실전 프로젝트에서 나타나는 데이터 모델의 표기법을 이용한 사례를 보도록 하자.
1차 정규화 사례 1
‘한 번의 주문에 여러 개의 제품을 주문한다’는 업무 규칙이 있는데 <그림 2>의 왼쪽 편과 같이 데이터 모델링을 했다고 가정해 보자. 왼쪽의 엔티티 타입은 하나의 주문에 여러 개의 제품이 존재하므로 주문번호, 주문일자, 배송요청일자의 동일한 속성 값이 주문한 제품의 수만큼 반복해서 저장될 것이다. 따라서 오른쪽과 같이 1차 정규화를 적용하여 중복속성 값을 제거한다.
<그림 2> 1차 정규화의 응용 1

이 사례의 특징은 주문의 PK(Primary Key)인 주문번호가 중복 속성 값을 가지기 때문에 PK를 가진 데이터베이스 테이블 생성이 불가능하다는 특징이 있다.
1차 정규화 사례 2
로우(Row) 단위로 1차 정규화가 안 된 모델은 PK의 유일성이 확보되지 않으므로 인해 실전 프로젝트에서는 거의 찾아보기가 힘들다. 반면 로우 단위로 중복된 내용을 컬럼 단위로 펼쳐 중복하는 경우가 아주 많이 발견된다. 1차 정규화의 응용이 된 형태로 볼 수 있다. 계층형 데이터베이스에서 이와 같은 형식의 모델링을 많이 했는데 관계형 데이터베이스에서도 이러한 형식으로 모델링을 진행하는 경우가 많이 발견된다.
<그림 3> 1차 정규화의 응용 2

<그림 3>의 모델을 보면 왼쪽 모델의 일재고 엔티티 타입에는 3개월 분에 대한 장기재고 수량, 주문수량, 금액, 주문금액이 차례대로 기술되어 있다. 이렇게 되면 장기재고 관리가 4개월 이상으로 늘어날 때 모델을 변경해야 하는 치명적이 결함이 있다. 따라서 오른쪽과 같이 1차 정규화를 통해 모델을 분리함으로써 업무 변형에 따른 데이터 모델의 확장성을 확보하도록 해야 한다.
2차 정규화(주식별자에 종속적이지 않은 속성의 분리)
1차 정규화를 진행했지만 속성 중에 주식별자에 종속적이지 않고 주식별자를 구성하는 속성의 일부에 종속적인 속성인, 부분종속 속성(PARTIAL DEPENDENCY ATTRIBUTE) 을 분리하는 것이 2차 정규화(SECOND NORMALIZATION)이다. 2차 정규화는 반드시 자신의 테이블을 주식별자를 구성하는 속성이 복합 식별자일 경우에만 대상이 되고 단일 식별자일 경우에는 2차 정규화 대상이 아니다.
2차 정규화 사례
여러 개의 속성이 주식별자로 구성되어 있을 때 일반속성 중에서 주식별자에 일부에만 종속적인 속성이 있을 경우 2차 정규화를 적용하여 엔티티 타입을 분리하도록 한다.
<그림 4> 2차 정규화 응용

<그림 4>의 모델은 고객번호에 종속적이지 않은 속성들을 분리하여 고객점포라는 새로운 엔티티 타입을 생성하였다. 실전 프로젝트에서는 코드 유형의 엔티티 타입들이 2차 정규화가 되지 않고 하나의 엔티티 타입으로 표현되는 경우가 많이 발견된다. 이 모델에서 함수종속 관계 표기법으로 표기하자면 고객번호 -> (고객명)으로 표시하여 별도의 엔티티 타입으로 분리할 수 있다.
3차 정규화(속성에 종속적인 속성 분리)
3차 정규화(third normalization)는 속성에 종속적인 속성을 분리하는 것이다. 즉 1차 정규화나 2차 정규화를 통해 분리된 테이블에서 속성 중 주식별자에 의해 종속적인 속성 중에서 다시 속성 간에 종속 관계가 발생되는 경우에 3차 정규화를 진행한다. 3차 정규화의 대상이 되는 속성들을 이전 종속(transitive dependence) 관계 속성이라고 한다. 이것은 곧 주식별자에 의해 종속적인 속성 중에서 다시 다른 속성을 결정하는 결정자가 존재하여 다른 속성이 이 결정자 속성에 종속적인 관계를 나타낸다.
3차 정규화 실전 적용
결정자 역할을 하는 일반 속성이 존재하고, 결정자 역할 속성에 의존하는 의존자가 존재하는 엔티티 타입은 3차 정규화의 대상이 된다.
<그림 5> 3차 정규화 응용

<그림 5>의 모델은 고객 엔티티 타입에 등록카드에 대한 정보가 포함되어 있는 모습이다. 등록카드번호가 결정자 역할을 하고 있고 등록카드사명과 등록카드유효일자가 의존자 역할을 하는 속성 간의 종속적인 속성이 발견되었으므로 3차 정규화의 대상이 되는 모델이다. 따라서 등록카드에 대한 내용에 대해 별도의 엔티티 타입을 도출한 오른쪽 모델로 만듦으로서 3차 정규화를 완성하였다. 실전 프로젝트에서는 1:1관계의 엔티티 타입이 하나로 통합이 되었거나 업무분석 과정에서 하나의 엔티티 타입에 많은 속성이 포함되어 있을 때 3차 정규화의 대상이 되는 경우가 많이 나타난다. 이 모델에서 함수종속 관계 표기법으로 표기하자면 등록카드번호 -> (등록카드사명, 등록카드유효일자)으로 표시하여 별도의 엔티티 타입으로 분리할 수 있다.
보이스-코드 정규화
1차 정규화, 2차 정규화, 3차 정규화는 모두 하나의 주식별자를 가졌을 때를 가정하여 진행하였다. 만약 하나의 테이블에 여러 개의 식별자가 존재하면 비록 1, 2, 3 정규형을 모두 만족하더라도 데이터를 조작하는 데 문제가 발생될 수 있다. 복잡한 식별자 관계에 의해 발생되는 문제를 해결하기 위해 3차 정규화를 보완한 보이스-코드 정규화(boyce-code normalization)를 진행한다.
보이스-코드 정규화란 테이블에 존재하는 식별자가 여러 개 존재할 경우 식별자가 중복되어 나타나는 현상을 제거하기 위해 정규화 작업을 진행한다.
BCNF 실전 적용
납품 엔티티 타입의 주식별자는 부품번호, 부품이름, 납품번호 세 개의 속성의 구성이 되어 있고 세 개의 속성을 구성한 주식별자는 납품수량, 납품단가에 대해 결정자 역할을 한다. 그런데 부품번호+납품번호 만으로도 납품수량, 납품단가에 대해 결정자 역할을 할 수도 있고 부품이름+납품번호 만으로도 납품수량, 납품단가에 대해 결정자 역할을 할 수도 있다. 또한 부품번호와 부품이름은 상호간에 결정자역할을 하는 특성을 가지고 있다. 이러한 성격을 이용하여 데이터 모델에서는 최소의 속성의 조합이 주식별자를 갖게 하도록 BCNF(Boyce Codd Normal Form)를 적용한다. 즉, 부품번호를 주식별자로 하여 하여 부품을 구성하거나 부품이름을 주식별자로 하여 부품 엔티티 타입을 분리하여 납품과 관계를 갖게 하는 형식으로 정규화를 진행하는 방식이 바로 보이스-코드 정규화 방법이 된다.
<그림 6> BCNF 정규화의 응용

개념적 설명은 무척 까다롭지만 실전 사례를 통해서는 쉽게 이해되는 부분이다. 다시 한 번 정리하면, 주식별자 속성 중에 주식별자의 유일성을 확보하는 최소한의 속성이 아닌 쓸데없이 추가된 속성을 분리하는 것이 보이스-코드 정규화라고 할 수 있다. 또한 주식별자 속성 중에 상호간의 함수종속 관계를 가지는 것을 분리한다. <그림 6>의 부품번호와 부품이름 사례처럼 단독으로 주식별자에 참여할 수 있으면서 상호간의 종속 관계가 있는 코드, 코드명을 생각하면 쉽게 이해될 수 있다. 주식별자 속성이 많아질수록 보이스-코드 정규화의 대상이 되는 경우가 나타나므로 개념을 잘 정리하여 실전에서 데이터 모델을 검증할 수 있도록 해야 한다.
4차 정규화(특정 속성 값에 따라 선택적인 속성의 분리)
보이스-코드 정규화까지 정규화 작업을 진행하면 함수의 종속성에 관한 작업은 모두 정리가 되었다. 이제 더 이상 속성 사이의 종속적인 관계로 인해 발생하는 정규화 작업은 필요하지 않게 되는 것이다. 그러나 하나의 테이블에 두 개 이상의 독립적인 다가속성(multi-valued attribute)이 존재하는 경우에 다가종속(multi-valued dependency)이 발생되어 문제가 생긴다. 다가종속이라는 단어를 해석하면, 하나의 속성 값에 두 개의 이상의 의미를 가지는 값을 가지는 것을 의미한다. 4차 정규화의 대상이 되는 경우는 실제 프로젝트에서는 독립적인 엔티티 타입을 설계할 때 발생하기 보다는 동시에 여러 개의 엔티티 타입과의 관계에서 발생되는 경우가 많이 있다.
4차 정규화의 실전 적용
<그림 7>과 같은 업무 규칙이 있다. ‘한 명의 사원은 여러 개의 프로젝트를 지원할 수 있다’ 그리고 ‘한 명의 사원은 여러 개의 기술을 보유할 수 있다’ 즉 사원과 프로젝트, 사원과 기술 간의 업무적인 관계의 규칙이 있는 경우이다. 이 업무 규칙은 보유하는 기술이 있다는 사실을 관리하고 보유한 기술은 지원한 프로젝트와는 아무런 상관이 없다는 것이 특징이다. 그럼에도 불구하고 <그림 7>의 왼쪽처럼 사원과 프로젝트와 기술 간의 관계를 모두 연결하면 4차 정규화의 규칙을 위배하여 어떤 사원이 새로운 기술을 습득하여 사원내역 엔티티 타입에 등록하려고 하면 마치 금방 습득한 기술을 가지고 어떤 프로젝트를 지원한 것처럼 값을 채워줘야만 하는 현상에 빠지게 된다. 따라서 필요하지 않은 조인 관계를 해소하기 위해 오른쪽 모델과 같이 업무 규칙에 적합하게 관계를 분리하는 방법이 4차 정규화이다.
<그림 7> 4차 정규화의 응용

4차 정규화가 실전 프로젝트에서 거의 나타나지 않는다고 하는 사람들이 많은데 필자가 파악하기로는 2차 정규화나 BCNF보다 더 많이 발생된다. 단, 4차 정규화를 하지 않고 개발을 하다가 새로운 값을 채울 경우에 값을 기본 값(default value)으로 지정해버리는 경우가 많이 있다. 참조무결성 제약조건(FK)를 데이터베이스 테이블에 걸지 않는 경우에 가능한데 구축단계 때 많은 프로젝트에서 이와 같은 편법으로 프로그램을 작성한다. 좋지 않은 경우이다. 이와 같은 경우 데이터모델에 나타난 관계가 실제 데이터에서 불가피하게 단절되어 나타나므로 무결성 체크가 불가능해진다. 설계단계 때 불필요한 관계에 의해 나타나는 4차 정규화의 대상 엔티티 타입을 검증하여 정규화를 적용하도록 해야 한다.
반정규화
논리적인 데이터 모델링 단계에서는 모든 엔티티 타입과 속성들을 정규화 규칙에 적절하게 분석하여 데이터 모델링을 수행한다. 이 단계는 실전 프로젝트에서는 분석단계 때 수행하는 경우가 많고 설계단계 때는 데이터베이스 성능을 고려하여 물리적인 데이터 모델링을 수행하는데 물리적인 데이터 모델링의 여러 개의 타스크 중에 반정규화를 수행하게 된다. 반정규화라고 하면, 일반적으로 다른 엔티티 타입에 있는 속성을 중복한 것만을 생각하는 경우가 많이 있다. 훨씬 많은 반정규화 유형이 있고 각각은 유용하게 활용될 수 있음을 알 수 있다.
반정규화란 정규화된 엔티티 타입, 속성, 관계에 대해 시스템의 성능향상과 개발(development)과 운영(maintenance)의 단순화를 위해 데이터모델을 조정하는 프로세스를 의미한다. 단순하게 정규화 규칙에 반대되는 개념으로만 생각한다면 속성의 중복 정도가 반정규화의 범위에 해당되지만 물리적인 성능을 고려한 반정규화의 개념으로 생각한다면 테이블 통합/분리, 속성 중복, 속성 추가, 관계 중복 등이 반정규화의 범위에 해당된다.
반정규화를 적용하기 전에 반드시 중요하게 고려해야 할 점은 데이터의 무결성을 유지시킬 수 있는 방안을 마련하고 반정규화를 적용해야 한다는 것이다. 시스템을 개발할 때는 성공적인 오픈을 위해 성능을 중요하게 여겨 여러 테이블에 속성들을 반정규화하는 경우가 많은데 반정규화를 많이 할수록 데이터의 무결성은 깨져 이상한 데이터가 많이 남아있거나 돈의 액수가 맞지 않거나 등록된 접수 건수가 맞지 않은 현상이 시스템을 운영하는 중에 점점 많이 발생하게 되어 나중에는 시스템을 사용하지 못하게 되는 경우가 발생된다. 데이터 무결성을 중요하게 생각하고 반정규화를 적용할 필요가 있다.
반정규화에 대한 실전 프로젝트 적용 사례
반정규화를 하는 대상으로는 테이블, 속성, 관계에 대해 적용할 수 있으며 꼭 테이블과 속성, 관계에 대해 중복으로 가져가는 방법만이 반정규화가 아니고 테이블, 속성, 관계를 추가하거나 분할할 수 있으며 제거할 수도 있다.
1차 정규화에 대한 반정규화
고객에 대한 엔티티 타입에 방문을 두 번까지 가능하다고 할 때 고객번호, 고객명이 중복 속성 값을 갖기 때문에 1차 정규화의 대상이 되어 중간에 있는 고객방문 엔티티 타입으로 1차 정규화가 되었다. 그러나 최대 2회까지 방문이 가능하다는 업무 규칙을 이용하여 성능과 단순성을 고려하여 오른쪽에 있는 1차 정규화에 대한 반정규화 엔티티 타입으로 설계된 예이다.
<그림 8> 1차 반정규화의 응용

최대 발생하는 값을 이용한 이와 같은 반정규화의 유형은 실전 프로젝트에서 빈번하게 사용되지만 최대 발생 값을 변할 수 있는 경우는 정규화된 모습으로 모델링해야 확장성(flexible)이 보장된다는 것을 기억해야 한다.
2차 정규화에 대한 반정규화
주식별자가 두 개 이상일 때 일부 주식별자 속성에 의존적인 속성을 분리하는 2차 정규화에서 조인에 의한 성능저하와 단순성 확보를 위해 반정규화를 적용할 수 있다.
<그림 9> 2차 반 정규화의 모델

<그림 9>의 모델은 일자별 매각 물건 엔티티 타입에서 매각 일자가 결정자가 되고 매각 장소와 매각 시간이 의존자가 된 함수 종속성이 존재하여 2차 정규화를 적용했다가 다시 조인에 의한 성능저하 예방과 단순성을 위해 다시 일자별매각물건이라는 엔티티 타입에 반정규화를 한 경우이다.
3차 정규화에 대한 반정규화
<그림 10>의 모델을 보면 수납이라고 하는 엔티티 타입은 속성간의 결정자(수납확인번호)와 의존자가 존재하는 3차 정규화의 대상이 되는 모습이다. 따라서 수납확인번호를 결정자로 하고 수납확인방법, 수납확인일자, 수납확인자사번을 속성으로 하는 3차 정규화를 적용하였다.
<그림 10> 3차 반정규화의 응용

반정규화를 하는 대상으로는 테이블, 속성, 관계에 대해 적용할 수 있으며 꼭 테이블과 속성, 관계에 대해 중복으로 가져가는 방법만이 반정규화가 아니고 테이블, 속성, 관계를 추가할 수도 있고 분할할 수도 있으며 제거할 수도 있다. 정규화에 위배되는 것은 아니지만 성능을 위해 적용하는 반정규화의 방법 테이블 통합/분리, 속성 중복, 관계 중복 등 여러 가지가 있을 수 있다.
이력의 최근 변경 속성 값 반정규화
<그림 11>의 모델은 공급자에 대한 전화번호, 메일주소, 위치 등에 대한 변경 정보를 각각 관리하는 현재 데이터와 이력 데이터에 대한 데이터 모델이다. 모든 속성 값이 중복이 없어 완벽히 정규화된 모습이지만 이력 모델이 정규화되어 있음으로 인해 최근 값을 처리하는 데 상당한 시간이 소요되고 SQL 구문도 복잡하게 된다. 따라서 데이터를 조회할 때는 프로세스의 대부분은 가장 최근 값을 참조한다는 성격을 이용하여 오른쪽과 같이 최근 값에 대한 속성 값만을 관리하기 위해 공급자 엔티티 타입에 전화번호, 메일주소, 위치에 대한 속성을 추가하였다.
<그림 11> 최근 변경 값 속성의 반정규화

<그림 11>에서 공급자번호 1001~1005에 해당하는 공급자번호, 공급자명, 전화번호, 메일주소, 위치에 대한 정보를 조회하면 다음과 같이 작성된다.
SELECT A.공급자명, B.전화번호, C.메일주소, D.위치 FROM 공급자 A, (SELECT X.공급자번호, X.전화번호 FROM 전화번호 X, (SELECT 공급자번호, MAX(순번) 순번 FROM 전화번호 WHERE 공급자번호 BETWEEN '1001' AND '1005' GROUP BY 공급자번호) Y WHERE X.공급자번호 = Y.공급자번호 … WHERE A.공급자번호 = B.공급자번호 AND A.공급자번호 = C.공급자번호 AND A.공급자번호 = D.공급자번호 AND A.공급자번호 BETWEEN '1001' AND '1005' SELECT 공급자명, 전화번호, 메일주소, 위치 FROM 공급자 WHERE 공급자번호 BETWEEN '1001' AND '1005' 정규화된 모델에서 SQL반정규화된 모델에서 SQL 반정규화
적절한 반정규화를 통해 성능도 훨씬 향상되었을 뿐만 아니라 SQL 구문도 비교가 안될 만큼 단순해졌음을 알 수 있다.
관계 반정규화
속성의 반정규화에서 데이터를 조회하는 경로를 단축하기 위해 일반속성(주식별자가 아닌)을 중복할 수도 있고 주식별자 속성을 중복할 수도 있다. 주식별자 속성의 중복 중 전체 주식별자를 이루는 전체 속성의 중복은 곧 관계의 중복을 의미한다. 관계의 반정규화는 인위적인 속성의 중복 없이 조회경로 단축을 통해 조인에 의한 데이터 처리 속도를 향상시키는 장점이 있다.
<그림 12>의 왼쪽은 고객, 주문, 주문목록, 배송 엔티티 타입이 정규화가 잘 되어 있고 관계도 업무 규칙에 따라 식별자 관계/비식별자 관계로 적절하게 설정되어 있다. 그런데 배송 엔티티 타입에 발생되는 프로세스가 데이터를 처리할 때 항상 고객에 있는 속성의 모든 정보를 참조해야 하는데 왼쪽 정규화된 모델에서는 항상 주문목록과 주문을 경유하여 고객정보를 처리함으로 조인에 의한 성능저하가 예상된다. 따라서 조회경로를 단축하기 위해 오른쪽과 같이 관계를 추가로 연결하여, 즉, 이미 고객->주문->주문목록->배송으로 관계는 연결되어 있지만 성능을 위해 고객->주문으로 직접 관계를 연결한 관계의 반정규화를 적용한 사례이다.
<그림 12> 관계의 반정규화

<그림 12>의 데이터 모델에 왼쪽에 있는 데이터 모델에 대해 배송일시와 고객번호, 고객명을 가져오는 SQL 문장을 작성하면 다음과 같이 작성될 수 있다.
SELECT D.고객번호, D.고객명, A.일시
FROM 배송 A, 주문목록 B, 주문 C, 고객 D
WHERE A.배송번호 = ‘20031001001’
AND 배송.주문번호 = 주문목록.주문번호
AND 배송.제품번호 = 주문목록.제품번호
AND 주문.주문번호 = 배송.주문번호
AND 고객.고객번호 = 주문.고객번호
간단한 고객에 관련된 정보를 읽어오는데 2개의 테이블을 필요하지 않게 읽은 경우이다. 오른쪽과 같이 관계가 중복된 경우는 배송일시와 고객번호, 고객명을 가져오기 위해 다음과 같이 SQL 문장을 구성할 수 있다.
SELECT B.고객번호, B.고객명, A.일시
FROM 배송 A, 고객 B
WHERE A.배송번호 = ‘20031001001’
AND 배송.고객번호 = 주문.고객번호
2개의 테이블에 대해서만 접근을 하므로 관계가 중복되지 않은 경우보다 훨씬 쉽게 SQL 문장도 구성되며 성능도 더 낫다. 테이블의 관계가 5단계 6단계까지 내려가면서 중간에 비식별자관계로 연결되어 있고 빈번하게 조인이 되는 경우라면 관계의 중복을 고려할 수 있다. 프로젝트 상황에 따라 관계의 반정규화는 성능과 단순성에 있어 매우 유용하다.
호두과자에는 호두가 있다!
중부지방을 경유하는 기차 여행을 하면 자주 호두과자를 먹게 된다. 붕어 없는 붕어빵과는 다르게 호두과자에는 호두 알갱이가 있어 제법 고소한 맛이 난다. 이처럼 관공서, 학교, 기업 등에 구축하는 데이터베이스가 견실하기 위해서는 잘 정리된 정규화 사상이 녹아져 있어 정규화 사상 맛이 나는 데이터 모델이어야 한다. 그리고 거기에 체계화된 방법과 타당성 있는 반정규화를 적용한 데이터 모델을 만들어 내야 한다. 이 일은 그렇게 해도 되는 선택적인 사항이 아니라 한 번 구축하면 변경이 불가능하고 잘못된 데이터베이스는 시간에 따라 엄청난 문제와 제정을 낭비하기 때문에 그렇게 해야 하는 당위성을 가지고 있는 중요한 작업이다.
그러기 위해서는 데이터 모델링을 수행하는 사람은 정규화/반정규화에 대해 거울로 자기 얼굴을 보듯 정확한 이해와 체계적인 사고를 바탕으로 데이터 모델링을 할 수 있는 능력을 가져야 한다. 이 글을 읽는 독자는 이론을 위한 이론, 학교시험에서 점수 획득을 위한 지식의 단계를 뛰어넘어 실전에서 무한한 가치를 창조해 내는 진정한 지식가치의 이론을 겸비하여 최고의 데이터 모델링을 수행하는 전문가가 되기를 희망한다.
'dev' 카테고리의 다른 글
| expression pattern (0) | 2008.08.01 |
|---|---|
| script class (0) | 2008.08.01 |
| jndi (0) | 2008.08.01 |
| ant (0) | 2008.07.25 |
| 정규식 (0) | 2008.07.25 |
▶ Conditions for deadlock
1. Mutual exclusion condition : Each resource is either currently assigned to exactly one process or is available.
2. Hold and wait condition : Processes currently holding resources granted earlier can request new resources.
3. No preemption condition : Resources previously granted cannot be forcibly taken away from a process.They must be explicitly released by the process holding them.
4. Circular wait condition : There must be a circular chain of two or more processes,each of which is waiting for a resource held by the next member of the chain.
▶ Dining Philosophers Problem
Each lawyer needs two chopsticks to eat. Each grabs chopstick on the right first.
What if all grab at the same time? Deadlock.
+
철학자들은 원형테이블을 공유하며, 이 테이블은 가가 한 철학자에 속하는 5개의 의자로 둘러 싸여 있다.
테이블 중앙에는 한사발의 밥이 있고, 테이블에는 다섯개의 젓가락이 놓여있다.
- 철학자가 생각할때는 다른 동료들과 상호작용하지 않는다.
- 철학자는 배가고프면 자신에 가장 가까이 있는 두개의 젓가락을 집으려고 시도한다.
(이미 옆사람의 손에 들어간 젓가락은 집을 수 없다.)
- 식사중에는 젓가락을 놓지않고, 식사를 마치면 젓가락 두개를 모두 놓고 다시 생각을 시작한다.
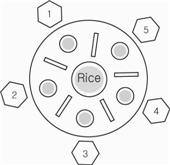
- 교착상태(deadlock)가 발생하는 4가지 필요조건에 '식사하는 철학자 문제'에 적용해보자.
철 학자는 배가고프면 자신에게 가까운 양쪽의 젓가락을 집어야한다. 하지만 옆의 다른 철학자가 이미 젓가락을 집어서 사용하고 있다면 그 젓가락은 이미 쓰고 있는 철학자만이 공유되지 않고 사용할 수 있기 때문에 배고픈 철학자는 옆의 철학자가 식사를 마치고 젓가락을 놓을 때까지 기다려야한다.
이것은 상호배제(mutual exclusion) 조건으로 최소한 하나의 자원이 비공유 모드로 점유되어 어느 자원에 대해 한 프로세스가 이미 사용중이면 다른 프로세스는 기다려야 하는 것을 보여준다.
또한 배고픈 철학자는 자신의 양 옆중 놓여있는 젓가락을 사용하기위해 하나 집고 다른 철학자가 쓰고 있는 다른 하나의 젓가락을 식사가 끝마쳐져서 놓여지기를 기다리는 경우는, 점유와 대기(Hold and wait) 조건으로 하나 이상의 자원을 할당받은 채로 나머지 자원을 할당 받기 위해 다른 프로세스의 자원이 해제되기를 기다리는 프로세스가 존재하는 경우이다.
젓가락은 미리 선점할 수 없는데, 즉 젓가락을 집고 있는 중 강제로 방출할 수 없다. 식사를 마친 철학자가 젓가락을 자발적으로만 놓을 수 있는 것이다. 이것은 자원을 할당받은 프로세스로부터 자원을 강제로 빼앗지 못하는 비선점(Nopreemption) 조건이다.
마지막으로, 철학자1은 철학자2가 가지고 있는 젓가락을 내려놓기를 기다리고 있고, 철학자2는 철학자3을, 철학자3은 철학자4를, 철학자4는 철학자5를,철학자5는 철학자1의 젓가락을 기다린다면 이것은 자원 할당 그래프 상에서 프로세스의 환형 사슬이 존재하는 것으로 순환대기(circular wait) 조건이다.
이 4가지 조건이 동시에 성립된다면 교착상태가 발생할 것이다.
- '식사하는 철학자 문제'에서 기아상태가 발생하는 경우.
철학자들은 식사를 하기 위해서 반드시 양쪽의 젓가락을 들어야한다.
위의 그림을 참고해서 보면, 철학자1과 철학자4가 식사를 시작하면, 철학자5는 식사를 하지못하고, 철학자2와 철학자4가 식사를 시작하게 되면 철학자3이 식사를 하지못하는 무한정 대기상태인 기아상태가 발생하게 된다.
'Algorithm' 카테고리의 다른 글
| 주소지정방식 (0) | 2008.08.19 |
|---|---|
| RISC 기본원리 (0) | 2008.08.19 |
| B-, B+ Tree (0) | 2008.08.01 |
| CPU scheduling (0) | 2008.08.01 |
| 스케쥴링 기법 (0) | 2008.08.01 |
▶ 다단계 색인의 가장 대표적인 색인 구조 B- 트리와 B+- 트리
B- 트리
B+- 트리
특 징
o 균형 m-원 탐색 트리
o 차수 m인 B-트리의 특성
- 루트와 리프를 제외한 노드의 서브트리 수 ≥ 2
* [m/2] ≤ 개수 ≤ m
- 모든 리프는 같은 레벨
- 키 값의 수
* 리프 : [m/2] -1 ~ (m-1)
* 리프가 아닌 노드 : 서브트리수 - 1
- 한 노드 내의 키값 : 오름차순
o 노드 구조
- Ki→ (Ki,Ai): 데이타 화일의 주소(Ai)
o 인덱스 세트 (index set)
- 내부 노드
- 리프에 있는 키들에 대한 경로 제공
- 직접처리 지원
o 순차 세트 (sequence set)
- 리프 노드
- 모든 키 값들을 포함
- 순차 세트는 순차적으로 연결
→ 순차처리 지원
- 내부 노드와 다른 구조
연
산
탐색
o 직접 탐색 : 키 값에 의존한 분기
- 순차 탐색 : 중위 순회
- 삽입, 삭제 : 트리의 균형 유지
- 분할 높이 증가
- 합병 높이 감소
- B+-트리의 인덱스 셀 = m-원 탐색 트리
- 리프에서 검색
삽입
리프노드
- 빈 공간이 있는 경우: 순 삽입
- 오버플로
* 두 노드로 분열(split)
* [m/2] 째의 키 값 → 부모노드
* 나머지는 반씩 나눔 (왼쪽, 오른쪽 서브트리)
- B-트리와 유사
- 오버플로우 (분열)
→ 부모 노드, 분열노드 모두에 키 값 존재
삭제
- 리프노드
- 삭제키가 리프가 아닌 노드에 존재
* 후행키 값과 자리교환(후행키-항상 리프에)
* 리프노드에서 삭제
- 언더플로 : 키수 < m/2�-1
* 재분배 (redistribution)
- 최소키 수 이상을 포함한 형제노드에서 이동
(형제노드의 키 → 부모노드 → 언더플로노드)
*합병 (merge)
- 재분배 불가능시 이용
(형제노드 + 부모노드의 키 + 언더플로노드)
리프에서만 삭제 (재분배, 합병 필요 없는 경우)
- 재분배: 인덱스 키 값 변화, 트리구조 유지
- 합병 : 인덱스의 키 값도 삭제
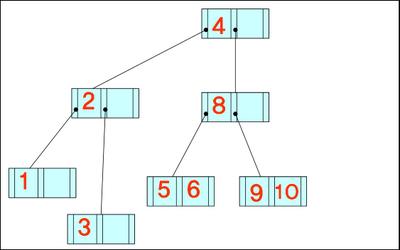
- 데이터가 왼쪽부터 차례대로 입력될 때 구축된 B-트리와 B+-트리의 최종적인 형태(차수는 3)
4, 8, 2, 3, 9, 7, 1, 6, 10, 5
B- 트리
B+- 트리
+ 위의 구축한 트리에서 키 값 7이 삭제된 후 모습
B-트리


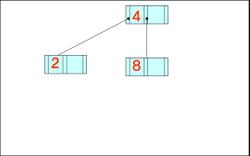


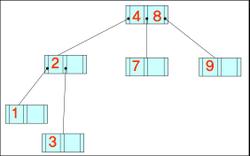
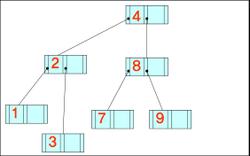





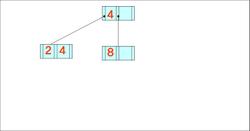

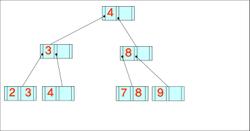


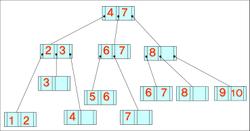
B+- 트리
'Algorithm' 카테고리의 다른 글
| RISC 기본원리 (0) | 2008.08.19 |
|---|---|
| deadlock 4가지 (0) | 2008.08.01 |
| CPU scheduling (0) | 2008.08.01 |
| 스케쥴링 기법 (0) | 2008.08.01 |
| banker's algorithm (1) | 2008.08.01 |
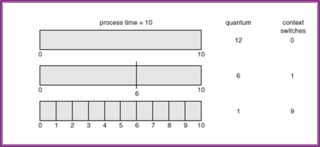
▶ Round Robin (RR)
- Each process gets a small unit of CPU time (time quantum), usually 10-100 milliseconds.
After this time has elapsed, the process is preempted and added to the end of the ready queue.
- If there are n processes in the ready queue and the time quantum is q,then each process gets 1/n of the CPU time in chunks of at most q time units at once.No process waits more than (n-1)q time units.- Performanceq large → FIFOq small → q must be large with respect to context switch, otherwise overhead is too high.+ 시간 할당량(time quantum) = 시간 조각(time slice)RR 스케줄링 알고리즘은 시분할 시스템을 위해 특별히 설계되었기 때문에, RR 스케줄링 알고리즘의 성능은 시간 할당량의 크기에 매우 많은 영향을 받는다. 극단적인 경우, 시간 할당량이 매우 크면, RR 정책은 선입선출 정채과 같다. 시간 할당량이 매우 적다면(예를 들어 1마이크로초), 라운드 로빈 방식은 처리기 공유(processor sharing) 라 불리며, 이론적으로는 n 개의 프로세스들 각각이 실제 처리기의 1/n 속도록 실행되는 자신의 처리기를 가지고 있는 것처럼 사용자에게 보인다.- 작은 시간 할당량은 문맥교환을 증가시킴을 보임또한, RR 스케줄링의 성능에 문맥교환(context switching)의 영향을 고려해야 할 필요가 있다. 우리가 10시간 단위를 갖는 하나의 프로세스를 가지고 있다고 가정해보자. 시간 할당량이 12시간 단위라면, 프로세스는 아무런 오버헤드 없이 1시간 할당량 이전에 끝난다. 만일 시간할당량이 6시간 단위라면, 프로세스는 2시간 할당량이 필요하므로, 한번 문맥교환을 해야한다. 시간할당량이 1시간 단위라면, 9번의 문백 교환이 발생할 것이고, 따라서 프로세스의 실행이 느려진다.그러므로, 우리는 시간 할당량이 문맥교환 시간에 비해 더 클 것을 원한다.- 총처리 시간이 time quantum에 따라 변함을 예시총처리 시간(turnaround time) 또한, 시간 할당량의 크기에 좌우된다. 한 프로세스 집합의 평균 총처리 시간은 시간 할당량의 크기가 증가하더라도 반드시 개선되지 않는다. 문맥 교환 시간이 추가된다면, 더 많은 문맥교환이 요구되기 때문에 더작은 시간 할당량에 대해서는 평균 총처리 시간이 증가된다. 반면에, 시간 할당량이 너무 크다면 RR 스케줄링은 선입 선처리 정책으로 퇴보한다.
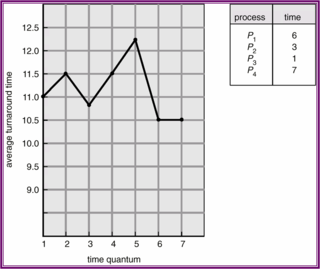
- A process can move between the various queues; aging can be implemented this way.- Multilevel-feedback-queue scheduler defined by the following parameters:ㆍnumber of queuesㆍscheduling algorithms for each queueㆍmethod used to determine when to upgrade a processㆍmethod used to determine when to demote a processㆍmethod used to determine which queue a process will enter when that process needs service+ 다단계 피드백 큐 (Multievel Feedback Queue) 스케줄링 수행 시 기대효과일반적으로 프로세스들이 스시템 진입 시에 영구적으로 하나의 큐에 할당되며, 큐사이를 프로세스들은 이동하지 않는다. 그러나 다단계 피드백 큐 스케줄링 알고리즘에서는 프로세스가 큐들 사이로 이동한다. 어떤 프로세스가 CPU 시간을 너무 많이 사용하면, 낮은 우선순위의 큐로 이동되고, 입/출력 중심의 프로세스와 대화형 프로세스들을 높은 우선순위의 큐에 넣어주어 효율이 향상되는 효과를 갖게 한다.
자세히 살펴보면, 준비된 큐를 다수의 분리된 큐로 나누고 각 큐에 우선순위를 연관시킨다. 우선순위가 낮을수록 큐에서 사용하는 time quantum는 증가된다. 각 큐의 프로세스들은 그 큐보다 높은 우선순위의 큐들이 empty인 경우에만 CPU를 할당받을 수 있다. 모든 프로세스들은 처음에는 highest priority queue에 들어간다.
만약 주어진 time quantum가 만기되면 실행되던 프로세스는 그 프로세스가 있었던 우선순위 큐의 바로 하위의 우선순위 큐로 이동된다. 따라서 CPU-bounded process는 점차 낮은 우선순위 큐로 이동된다. lowest priority queue의 프로세스에 대해 time quantum가 만기된 경우였다면 그 프로세스는 다시 lowest priority queue에 들어간다.
만약 프로세스가 I/O 종료 후 다시 큐로 들어가야 한다면 그 프로세스는 I/O 요청 이전에 있었던 우선순위 큐의 바로 상위의 우선순위 큐에 들어간다. 따라서 I/O-bounded process는 점차 높은 우선순위 큐로 이동된다. highest-priority queue의 프로세스에 대해 I/O 종료가 발생한 경우였다면 그 프로세스는 다시 highest priority queue에 들어간다.
+ 다단계 피드백 큐 스케줄링과 기아상태
스케줄링 수행시 실행 준비는 되어 있으나 CPU를 사용하지 못하는 프로세스는 CPU를 기다리면서 봉쇄된 것으로 간주될 수 있다. 예를 들면,부하가 과중한 컴퓨터 시스템에서 높은 우선순위의 프로세스들이 꾸준히 들어와 낮은 우선순위의 프로세스들이 CPU를 얻지 못하게 됨으로써, 낮은 순위의 프로세스들은 무한봉쇄(indefinite blocking) 또는 기아상태(starvation)가 되는 것이다.
낮은 우선순위의 프로세스들을 무한히 봉쇄하는 문제(기아상태)에 대한 해결방안은 노화(aging)이다. 노화란, 오랫동안 시스템에서 대기하는 프로세스들의 우선순위를 점진적으로 증가시키는 방법으로, 다단계 피드백 큐 스케줄링 수행시 낮은 우선순위의 큐에서 너무 오래 대기하는 프로세스는 높은 우선순위의 큐로 이동하여 기아상태를 예방할 수 있다.

높은 우선순위의 프로세스가 현재 낮은 우선순위의 프로세스에 의해 접그되고 있는 커널 자료를 읽거나 변경할 필요가 있을 경우 어떠한 일이 발생할 수 있을까? 이때 높은 우선순위의 프로세스는 낮은 우선순위의 프로세스가 끝나기를 기다려야 한다. 이는 우선순위 역전(inversion) 이라고 알려져 있다. 사실, 높은 우선순위의 프로세스가 필요로 하는 자원들을 접근하고 있는 프로세스들의 체인이 있을 수 있다.
이러한 문제는, 이러한 모든 프로세스들(높은 우선순위 프로세스가 필요로 하는 자원을 접근하는 모든 프로세스들) 이 그 자원을 사용 완료할 때까지 높은 우선순위를 상속하는, 우선순위 상속(priority-inheritance) 프로토콜로 해결할 수 있다. 이들은 종료할 때 우선순위가 원래의 값으로 복귀한다.
- 경성 실시간 시스템(Hard real-time system)ㆍ정해진 시간 내에 특정 작업이 완료되기를 요구한다.ㆍresource reservation : scheduler는 process가 정해진 시간 내에 완료되는 것이 보장될 경우 수행하고, 그렇지 않으면 요청을 거절한다.ㆍ현대의 computer와 운영체제에는 완전한 기능성은 갖추어 있지 않으며 특정 process를 위해서 사용되는 hardware 상에서 실행되는 특수 목적의 software로 구성된다.ㆍ단점 : scheduler가 각 type의 운영체제 기능이 수행되기 위해 얼마나 오랜 시간이 소요되는지 정확하게 알아야만 한다. 따라서 각 operation이 최대 시간을 취할 수 있도록 보장해야 한다. 그러나 이러한 보장은 secondary storage나 virtual memory를 가진 system에서는 불가능하다.
- 연성 실시간 시스템(Soft real-time system)
ㆍhard real-time system 보다는 덜 제한적이다. 중요한 process들이 상대적으로 덜 중요한 process들 보다 높은 priority를 가질 것을 요구한다.
ㆍ단점 : time-sharing system에 soft real-time 기능을 첨가하는 것은 자원의 불공정한 할당을 야기할 수도 있으며 더 긴 지연이나 심지어는 starvation을 초래할 수도 있다.
'Algorithm' 카테고리의 다른 글
| deadlock 4가지 (0) | 2008.08.01 |
|---|---|
| B-, B+ Tree (0) | 2008.08.01 |
| 스케쥴링 기법 (0) | 2008.08.01 |
| banker's algorithm (1) | 2008.08.01 |
| deadlock (0) | 2008.08.01 |




